
# Pod
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。 Pod 是一组容器,一个 pod 的所有容器共享 pod 的网路,存储 以及运行容器的声明。
通常用户需要直接创建 Pod , 而是使用负载资源来替用户管理一组 Pod . 这些负载资源通过配置 控制器 来确保正确类型的、处于运行状态的 Pod 个数是正确的,与用户所指定的状态相一致。
# 控制器
# Replication Controller 和 ReplicaSet
ReplicationController(RC) 用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退
出,会自动创建新的 Pod 来替代;而如果异常多出来的容器也会自动回收;
在新版本的 Kubernetes 中建议使用 ReplicaSet 来取代 ReplicationController 。 ReplicaSet 跟
ReplicationController 没有本质的不同,只是名字不一样,并且 ReplicaSet 支持集合式的 selector .
# 实验
1 | apiVersion: apps/v1 |
-
查看 当前的
pod
![]()
-
新开一个窗口,使用命令:
kubectl get pod -o wide -w来查看 pod 的变化过程.
![]()
-
然后使用命令
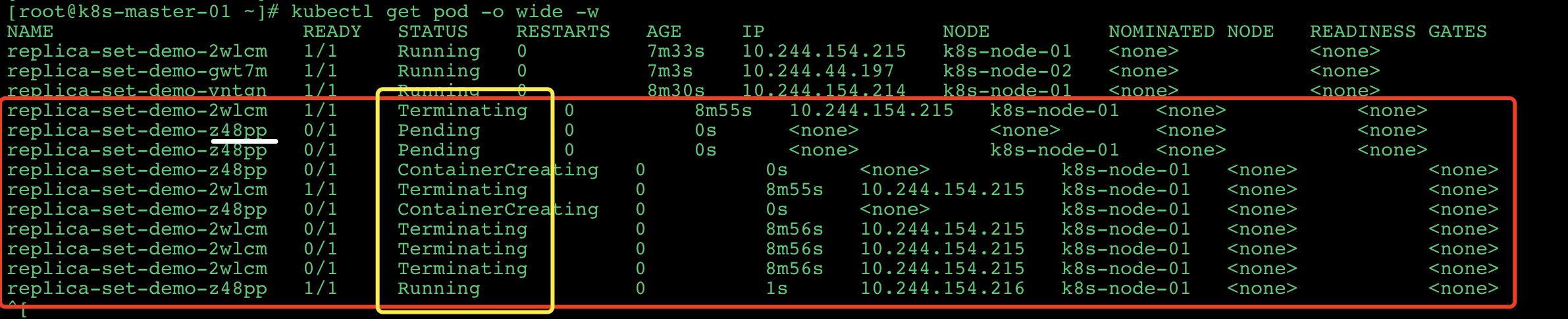
kubectl delete pod replica-set-demo-2wlcm删除其中的任意一个pod -
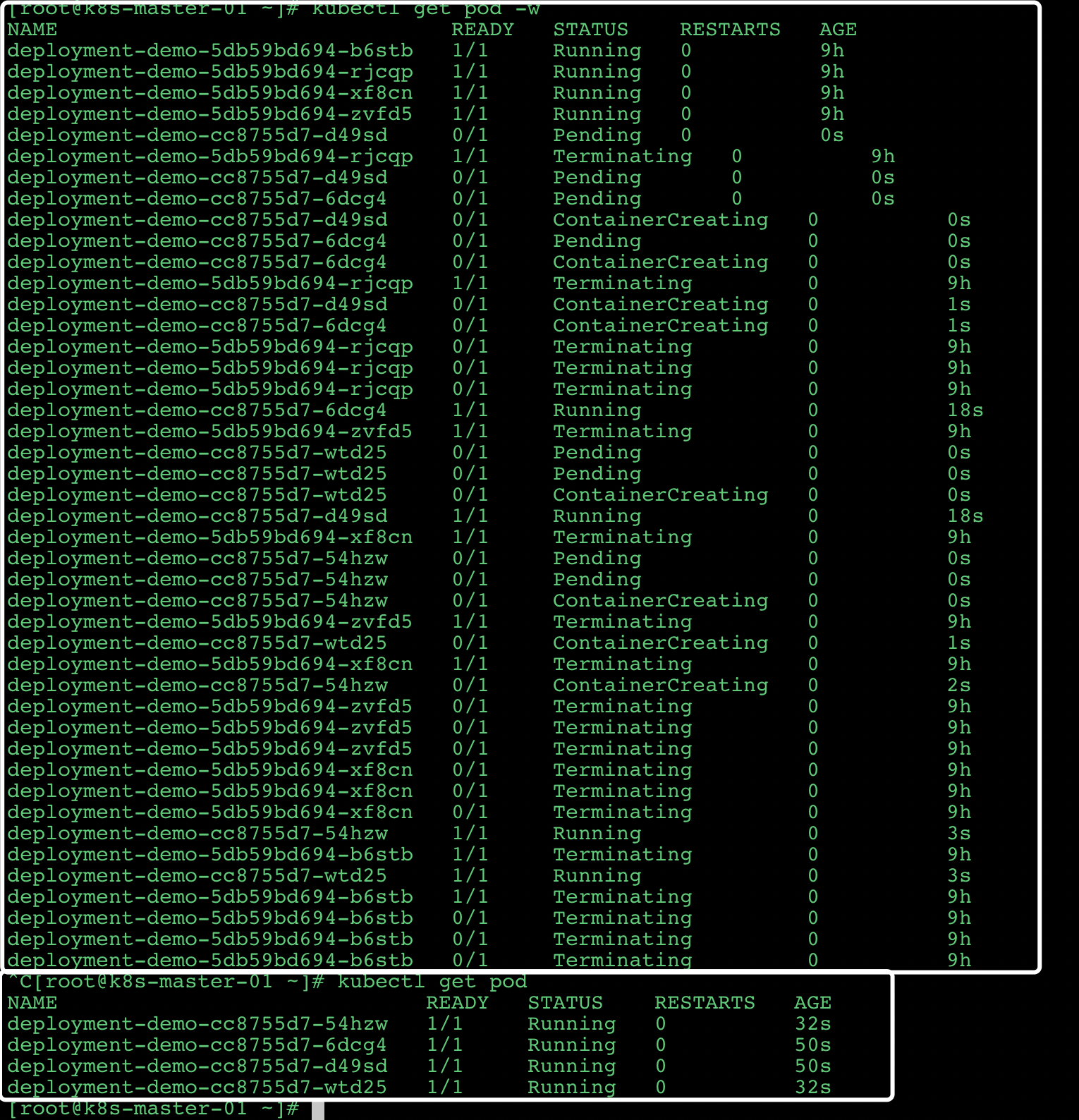
然后 可以看到新窗口中出现了如下的变化:
![]()
删除的pod(2wlcm) 先从Running变成了Terminating, 然后启动了一个新的pod (z48pp), 状态从Pending->ContainerCreating->Running.


# 修改标签
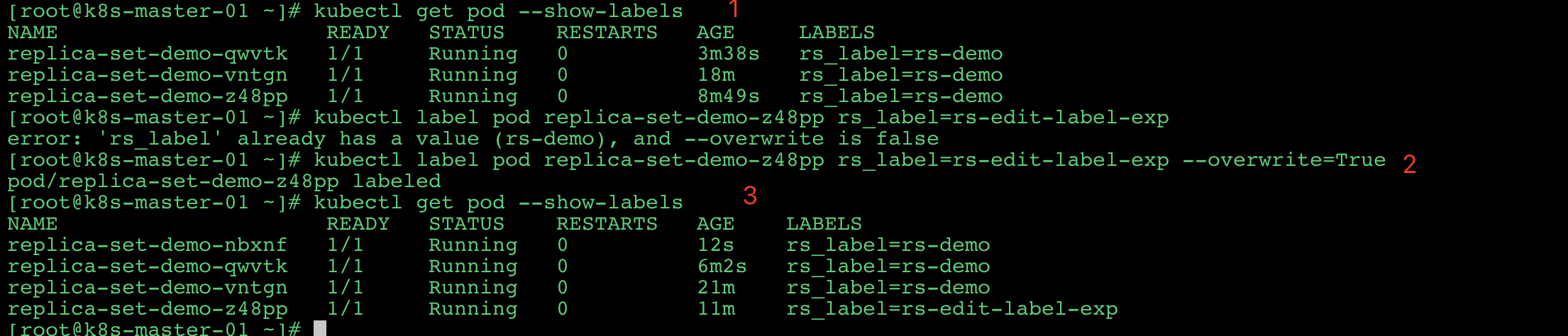
- 通过命令
kubectl get pod --show-labels查看pod的标签。 - 通过命令
kubectl label pod replica-set-demo-z48pp rs_label=rs-edit-label-exp --overwrite=True修改pod的标签。 - 查看
pod
发现 新启动了一个 pod , 如上图中的 (Pod)nbxnf 。此时 原来的 pod 就变成了新的标签。
由此可以看出: ReplicaSet 是通过 labels 来判断 pod 是否属于当前的 RS 的。
那 新建一个相同标签的 pod 会发生什么呢?
# 修改回原来的标签
我先把 标签修改成原来的 kubectl label pod replica-set-demo-z48pp rs_label=rs-demo --overwrite=True
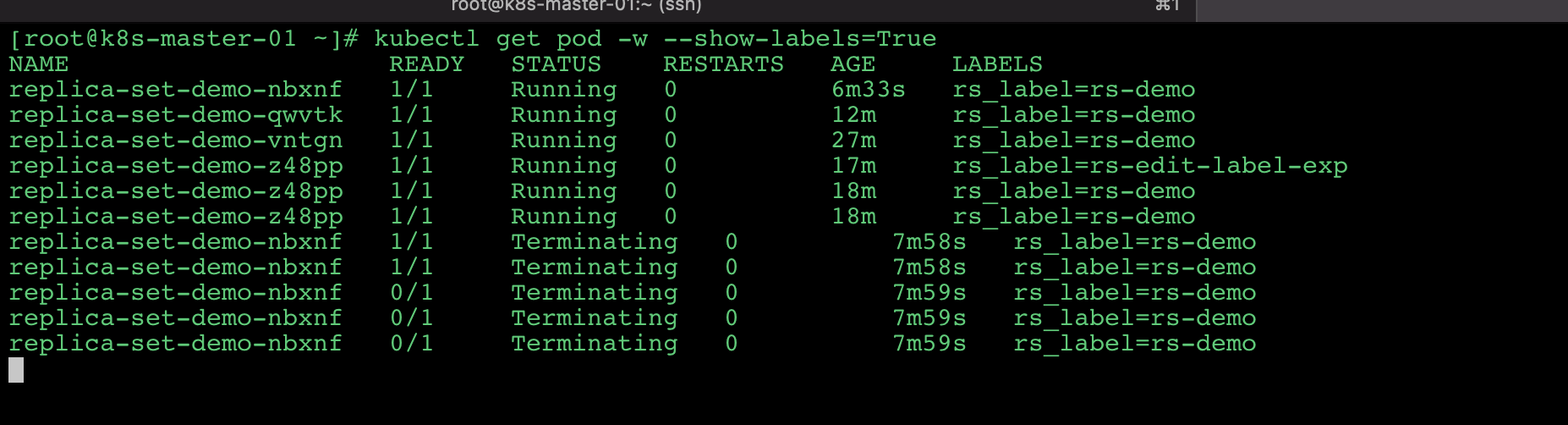
k8s 删掉了最新创建的那个容器。
# 新建一个相同标签的 pod 容器
1 | apiVersion: v1 |
创建这个容器之后,会发现
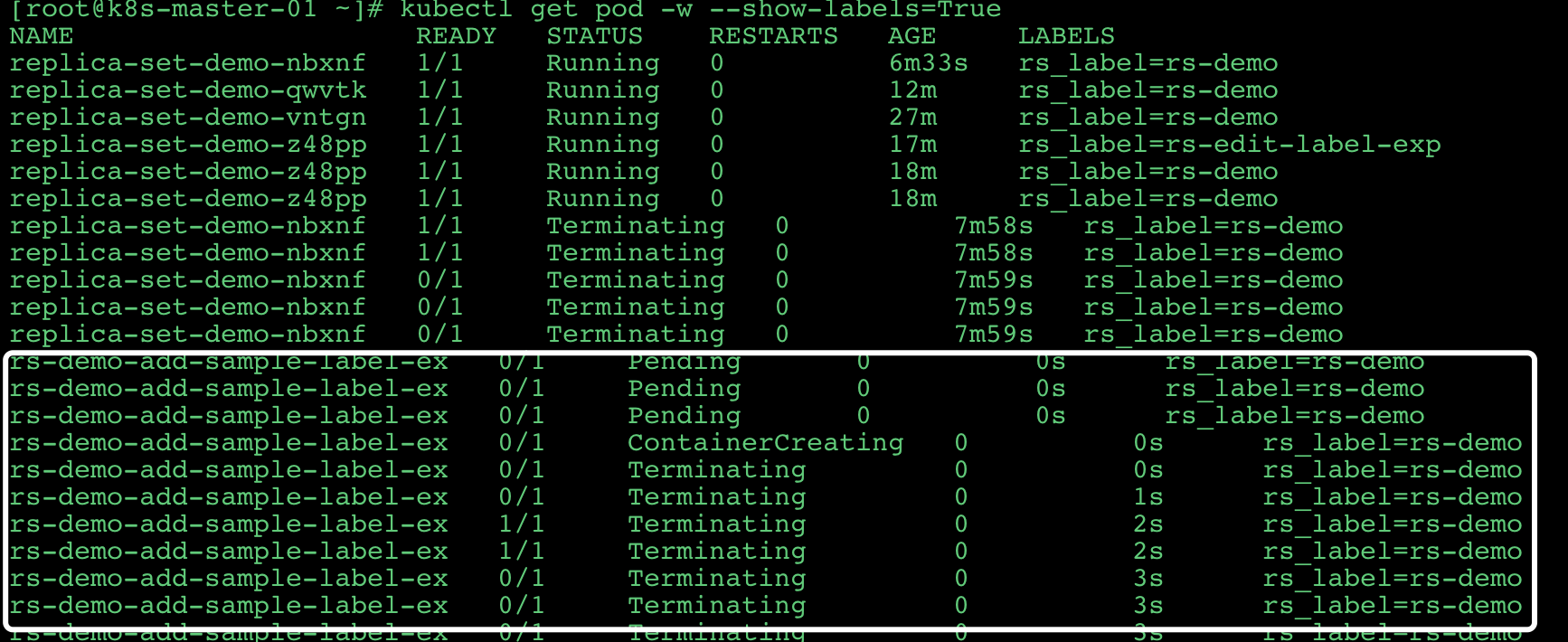
这个容器在创建时机就会被 kill 掉。
# 删除 ReplicaSet
使用命令 kubectl delete rs replica-set-demo 删除即可.
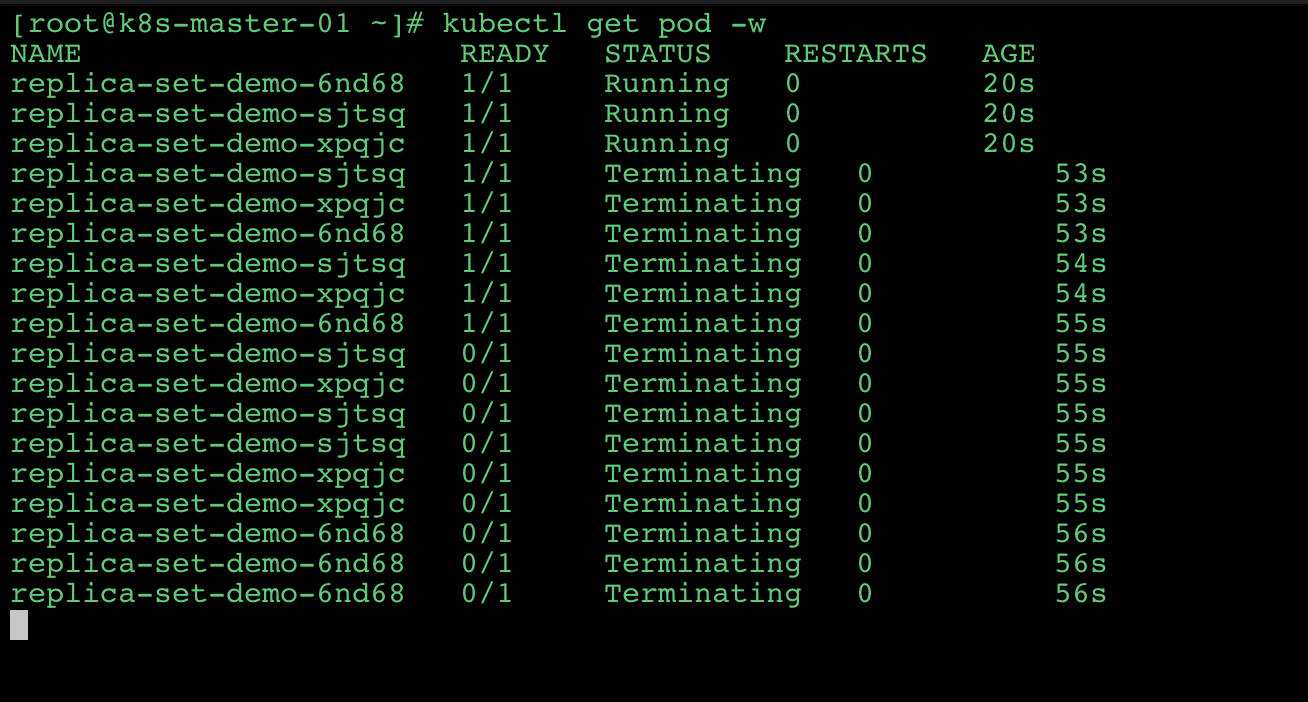
# Deployment
Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义 ( declarative ) 方法,用来替代以前的 ReplicationController 来方便的管理应用。典型的应用场景包括;
- 定义
Deployment来创建Pod和ReplicaSet - 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续
Deployment.
# 升级策略
Deployment 可以保证在升级时只有一定数量的 Pod 是 down 的。默认的,它会确保至少有比期望的 Pod 数量少一个是 up 状态 (最多一个不可用)
Deployment 同时也可以确保只创建出超过期望数量的一定数量的 Pod 。默认的,它会确保最多比期望的 Pod 数
量多一个的 Pod 是 up 的 (最多 1 个 surge )
未来的 Kuberentes 版本中,将从 1-1 变成 25%-25%
# 实验
# 创建 Deployment
1 | apiVersion: apps/v1 |
- 使用命令
kubectl get pod -w监听 Pod 的变化 - 使用命令
kubectl apply -f 07-deployment-demo.yaml创建deployment
![]()
- 查看对应
Pod的变化。
![]()

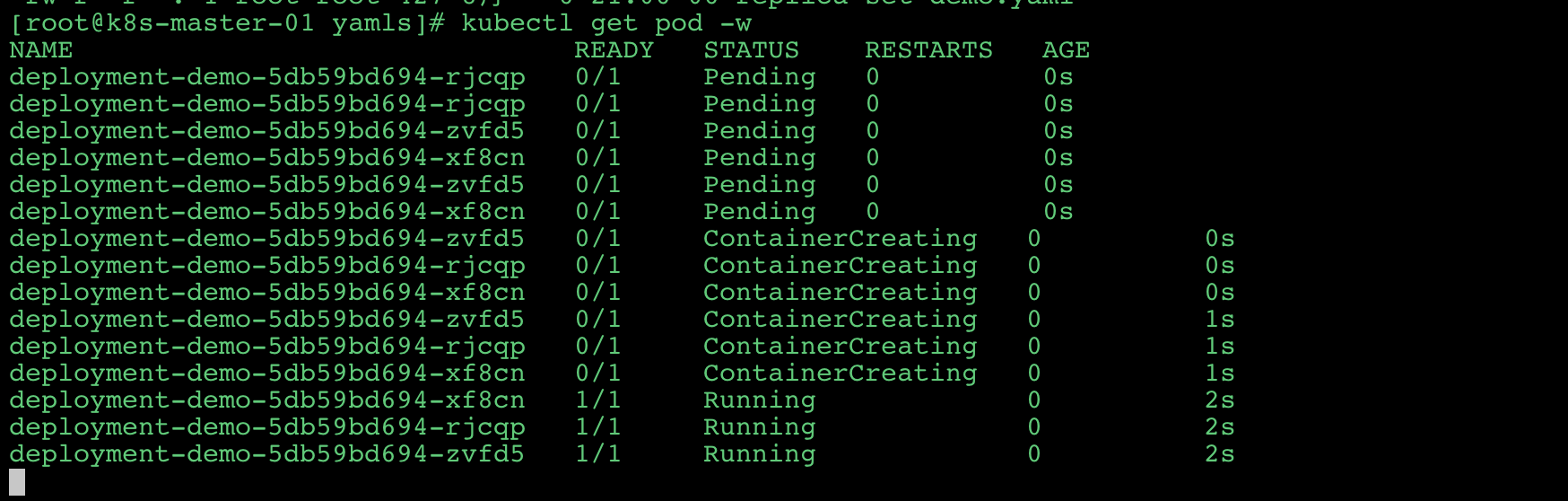
# 扩缩容
下面我们先演示一个比较简单的案例,扩缩容。
1 | kubectl scale deployment deployment-demo --replicas=4 |
如果集群支持自动扩容的话,还可以为集群设置 autoscaling .
1 | kubectl autoscale deployment xxx --min=10 --max=15 --cpu-percent=80 |
# 设置镜像
1 | kubectl set image xxxx imagesName:v1 |
具体如何操作接着往下看。
# 滚动升级
在真是的业务场景中,大部分都是通过设置升级镜像的版本来触发 deployment 的升级.
- 使用命令
kubectl set image deployment/deployment-demo deployment-demo-container=fangjiaxiaobai/my-app:v2修改deployment的版本。
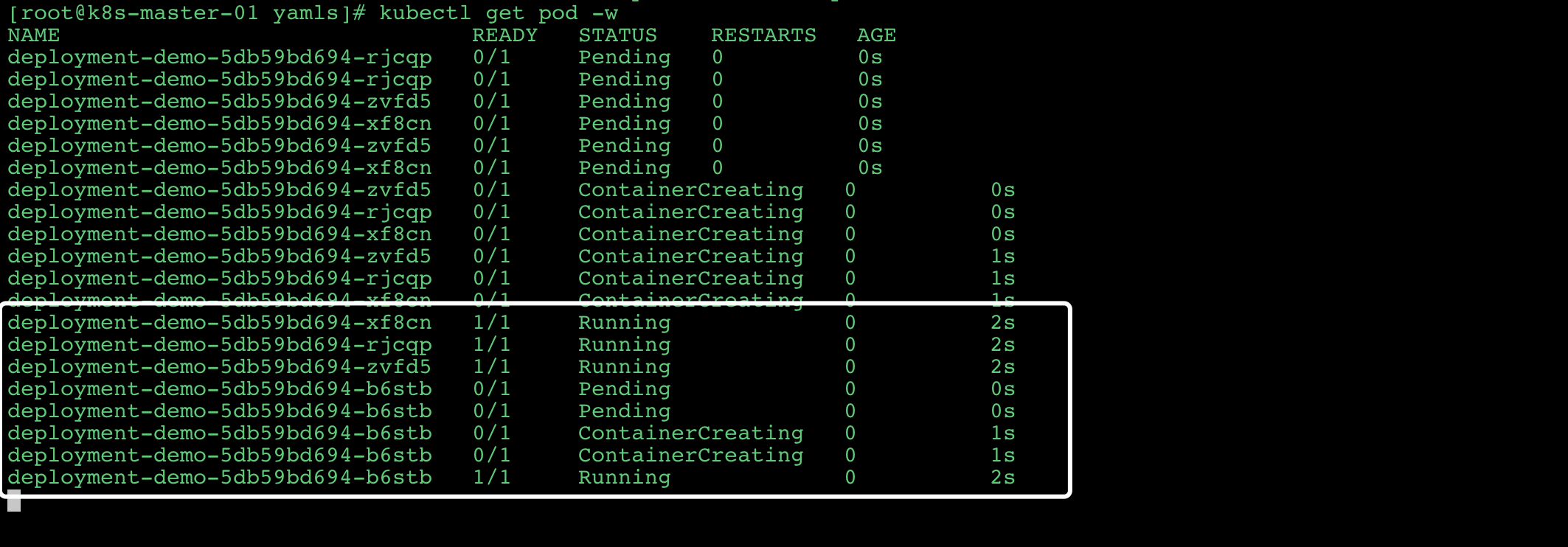
![]()
- 查看
Deployment的变化过程
![]()
可以看到k8s先启动一个pod, 然后kill一个pod. 最终完成整个Deployment的更新。 - 然后,我们访问一下页面,看一个应用的版本
![]()


# 回滚 rollover
- 使用命令
kubectl rollout undo deployment/deployment-demo将Deployment回滚到上一次的版本

可以看到已经回滚到了 V1 版本。
# 清理策略
可以通过设置 .spec.revisonHistoryLimit 来指定 deploymenet 最多保留 revison 历史版本。默认会保留所有历史版本,如果设置为 0 , 则 Deployment 就不允许回滚了。
命令式编程 和 命令式编程
- 命令式编程:它侧重于 如何实现程序,就像我们刚接触编程的时候那样,我们需要把程序的实现过程按照逻辑一步步写下来。面向过程编程。
- 声明式编程:它侧重于定义想要什么,然后告诉计算机 / 引擎,让他帮你去实现。 面向对象编程.
# Daemonset
DaemonSet 确保全部 (或者一些) Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod . 使用 DaemonSet 的一些典型用法:
- 运行集群存储
daemon,例如在每个Node上运行glusterd、ceph - 在每个
Node上运行日志收集daemon,例如fluentd、logstash - 在每个
Node上运行监控daemon,例如 Prometheus Node Exporter、collectd、Datadog代理、New Relic代理,或Ganglia gmond
1 | apiVersion: apps/v1 |

# Job
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束
- 特殊说明
spec.template: 格式同pod.RestartPolicy: 仅支持Never或者OnFailure.- 单个
Pod时 默认Pod成功运行后Job即结束。 .spec.completios: 标志 Job 结束时需要成功运行的Pod个数。.spec.parallelism: 标识 并行运行的pod的个数,默认为 1.spec.activeDeadlineSeconds: 标识失败Pod重试的最后间隔时间,超过这个时间将不会再重试
# 实验
- 创建一个 Job
1 | apiVersion: batch/v1 |

# Cron Job
Cron Job 管理基于时间的 Job ,即:
在给定时间点只运行一次
周期性地在给定时间点运行
使用前提条件: 当前使用的 Kubernetes 集群,版本 >= 1.8 (对 CronJob)。对于先前版本的集群,版本 < 1.8,启动 API Server 时,通过传递选项 --runtime-config=batch/v2alpha1=true 可以开启 batch/v2alpha1 API
典型的用法如下所示:
- 在给定的时间点调度
Job运行 - 创建周期性运行的
Job,例如:数据库备份、发送邮件
# 特殊说明
spec.schedule:调度,必需字段,指定任务运行周期,格式同Cronspec.jobTemplate:Job模板,必需字段,指定需要运行的任务,格式同Jobspec.startingDeadlineSeconds:启动Job的期限(秒级别),该字段是可选的。如果因为任何原因而错
过了被调度的时间,那么错过执行时间的Job将被认为是失败的。如果没有指定,则没有期限spec.concurrencyPolicy:并发策略,该字段也是可选的。它指定了如何处理被Cron Job创建的Job的并发执行。只允许指定下面策略中的一种:Allow(默认):允许并发运行JobForbid:禁止并发运行,如果前一个还没有完成,则直接跳过下一个Replace:取消当前正在运行的Job,用一个新的来替换。
注意,当前策略只能应用于同一个Cron Job创建的Job。如果存在多个Cron Job,它们创建的Job之间总是允许并发运行。
spec.suspend:挂起,该字段也是可选的。如果设置为true,后续所有执行都会被挂起。它对已经开始执行的Job不起作用。默认值为false。spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit:历史限制,是可选的字段。它们指定了可以保留多少完成和失败的Job。默认情况下,它们分别设置为3和1。设置限制的值为0,相关类型的Job完成后将不会被保留。
# 实验
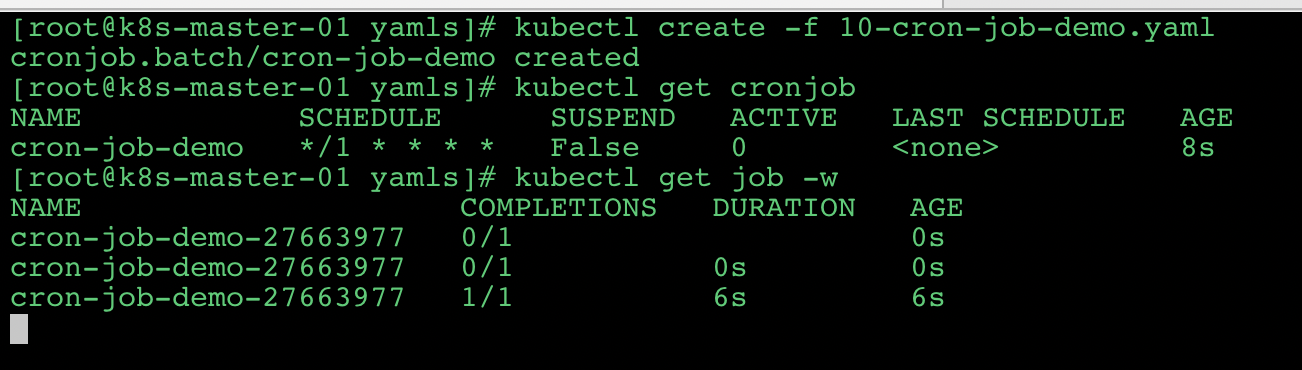
# 创建 CronJob
1 | apiVersion: batch/v1 |
然后可以查看一个 pod 的运行情况:
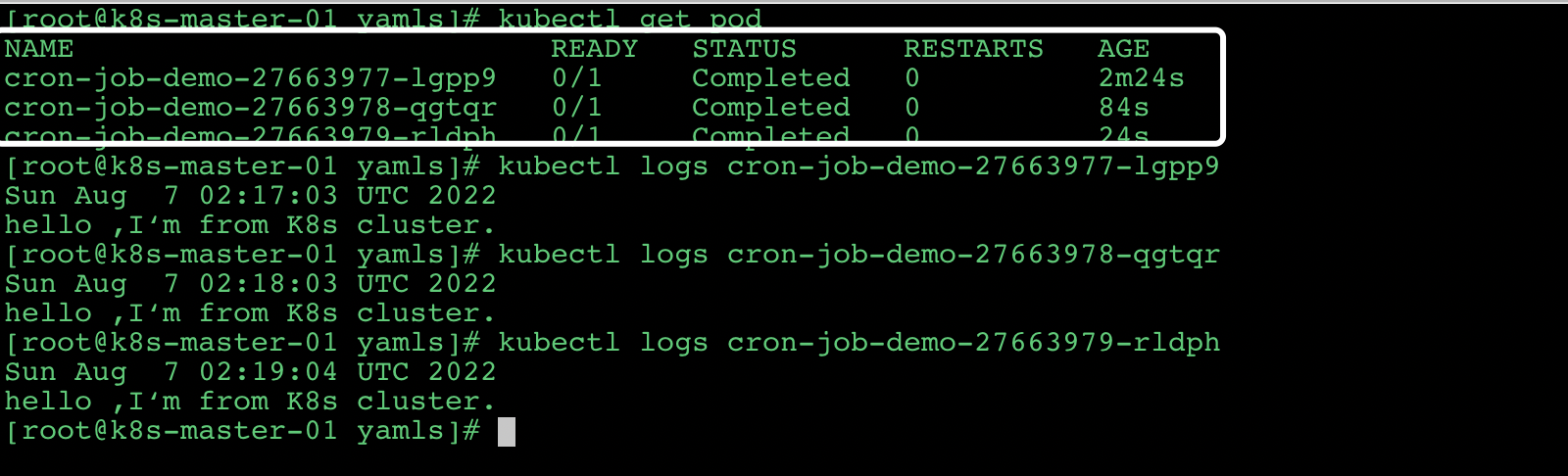
每个 job 都是相隔一分钟执行一次。
# StatefulSet
StatefulSet 作为 Controller 为 Pod 提供唯一的标识。它可以保证部署和 scale 的顺序
StatefulSet 是为了解决有状态服务的问题 (对应 Deployments 和 ReplicaSets 是为无状态服务而设计),其应用 场景包括:
- 稳定的持久化存储,即
Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service) 来实现。 - 有序部署,有序扩展,即
Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行 (即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实 现
有序收缩,有序删除 (即从N-1到0)
# Horizontal Pod Autoscaling
应用的资源使用率通常都有高峰和低谷的时候,如何削峰填谷,提高集群的整体资源利用率,让 service 中的 Pod 个数自动调整呢?这就有赖于 Horizontal Pod Autoscaling 了,顾名思义,使 Pod 水平自动缩放
文中所有的 k8s yaml 配置文件均可从 https://github.com/fangjiaxiaobai/k8s/tree/main/yamls 获取。
# 最后
希望和你一起遇见更好的自己

