
https://github.com/golang/glog ,是 google 提供的一个不维护的日志库, glog 有其他语言的一些版本,对我当时使用 log 库有很大的影响。它包含如下日志级别: Info , Warning , Error , Fatal (会中断程序执行)
还有类似 log4go , loggo , zap 等其他第三方日志库,他们还提供了设置日志级别的可见行,一般提供日志级别: Trace , Debug , Info , Warning , Error , Critical .
# 日志级别
# Warning
没人看警告,因为从定义上讲,没有什么出错。也许将来会出问题,但这听起来像是别人的问题。我们尽可能的消除警告级别,它要么是一条信息性消息,要么是一个错误。我们参考 Go 语言设计额哲学,所有警告都是错误,其他语言的 warning 都可以忽略,除非 IDE 或者在 CICD 流程中强制他们为 error ,然后逼着程序员们尽可能去消除。同样的,如果想要最终消除 warning 可以记录为 error ,让代码作者重视起来。
# Fatal
记录消息后,直接调用 os.Exit(1) ,这意味着: 在其他 goroutine defer 语句不会被执行; 各种 buffers 不会被 flush ,包括日志的; 临时文件或者目录不会被移除; 不要使用 fatal 记录日志,而是向调用者返回错误。如果错误一直持续到 main.main 。 main.main 那就是在退出之前做处理任何清理操作的正确位置。
# Error
也有很多人,在错误发生的地方要立马记录日志,尤其要使用 error 级别记录。

# 处理 error
把 error 抛给调用者,在顶部打印日志;
如果您选择通过日志记录来处理错误,那么根据定义,它不再是一个错误 — 您已经处理了它。记录错误的行为会处理错误,因此不再适合将其记录为错误。

# DEBUG
相信只有两件事你应该记录:
- 开发人员在开发或调试软件时关心的事情。
- 用户在使用软件时关心的事情。
显然,它们分别是调试和信息级别。
log.Info 只需将该行写入日志输出。不应该有关闭它的选项,因为用户只应该被告知对他们有用的事情。如果发生了一个无法处理的错误,它就会抛出到 main.main 。 main.main 程序终止的地方。在最后的日志消息前面插入 fatal 前缀,或者直接写入 os.Stderr 。
log.Debug ,是完全不同的事情。它由开发人员或支持工程师控制。在开发过程中,调试语句应该是丰富的,而不必求助于 trace 或 debug2 (您知道自己是谁)级别。日志包应该支持细粒度控制,以启用或禁用调试,并且只在包或更精细的范围内启用或禁用调试语句。
B 站的 go 框架是如何设计和思考的:https://github.com/go-kratos/kratos/tree/v2.0.x/log
# 日志选型
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据;
- 传输-能够稳定的把日志数据传输到中央系统;
- 存储-如何存储日志数据;
- 分析-可以支持
UI分析; - 警告-能够提供错误报告,监控机制;
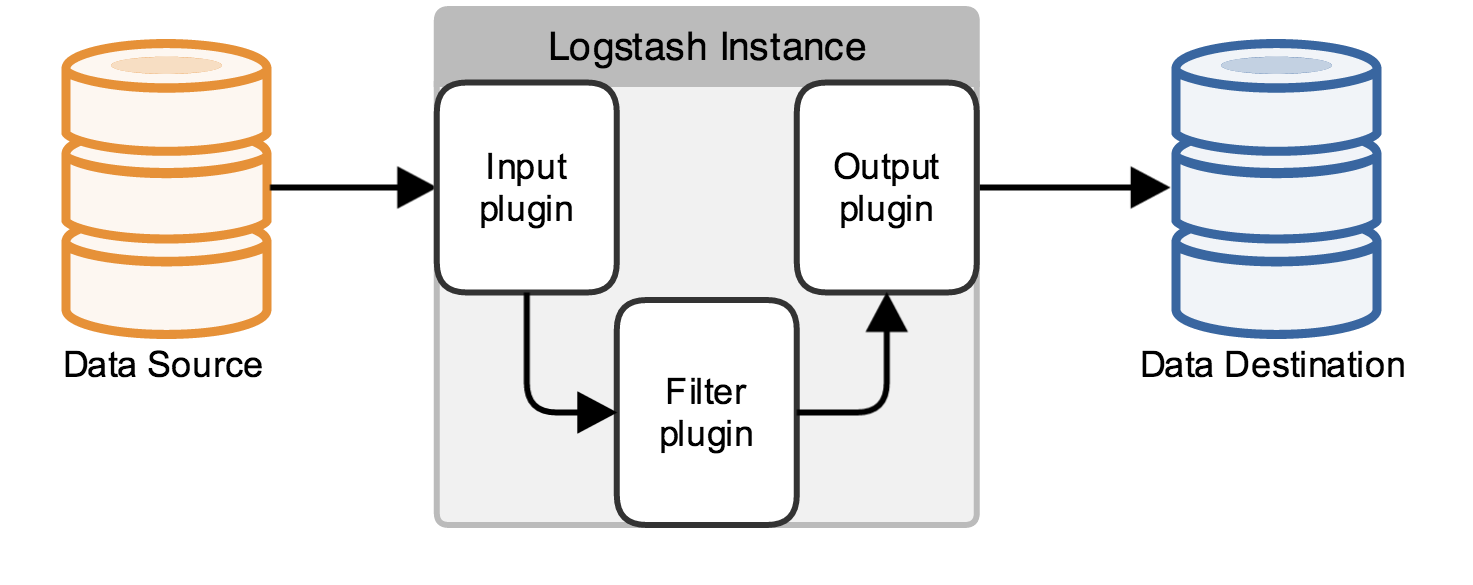
开源界鼎鼎大名 ELK stack ,分别表示: Elasticsearch , Logstash , Kibana , 它们都是开源软件。新增了一个 FileBeat ,它是一个轻量级的日志收集处理工具 ( Agent ), Filebeat 占用资源少,适合于在各个服务器上搜集日志后传输给 Logstash ,官方也推荐此工具。
# ELK
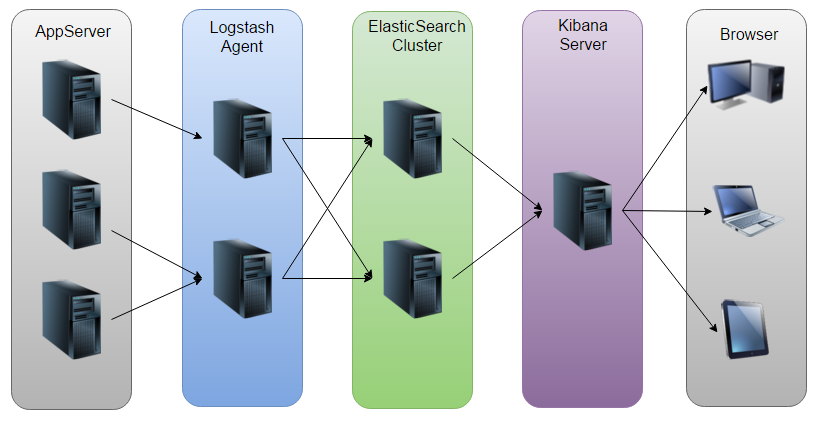
此架构由 Logstash 分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的 Elasticsearch 进行存储。
Elasticsearch 将数据以分片的形式压缩存储并提供多种 API 供用户查询,操作。用户亦可以更直观的通过配置 Kibana Web 方便的对日志查询,并根据数据生成报表。
因为 logstash 属于 server 角色,必然出现流量集中式的热点问题,因此我们不建议使用这种部署方式,同时因为 还需要做大量 match 操作(格式化日志),消耗的 CPU 也很多,不利于 scale out 。
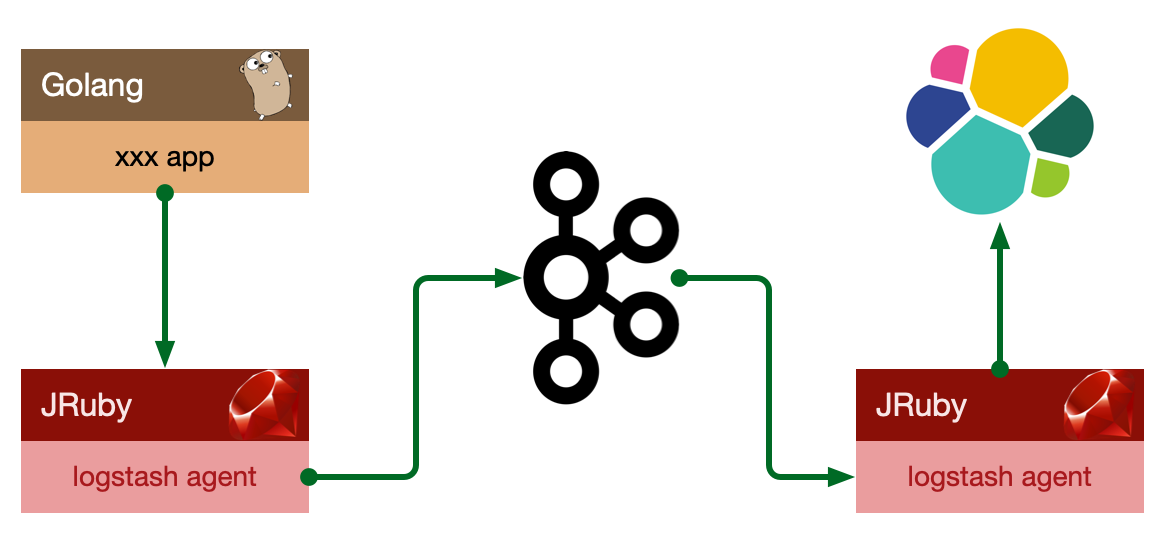
此种架构引入了消息队列机制,位于各个节点上的 Logstash Agent 先将数据 / 日志传递给 Kafka ,并将队列中消息或数据间接传递给 Logstash , Logstash 过滤、分析后将数据传递给 Elasticsearch 存储。最后由 Kibana 将日志和数据呈现给用户。因为引入了 Kafka ,所以即使远端 Logstash server 因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
更进一步的: 将收集端 logstash 替换为 beats , 更灵活,消耗资源更少,扩展性更强。
# 日志系统的设计目标
- 接入方式收敛;
- 日志格式规范;
- 日志解析对日志系统透明;
- 系统高吞吐、低延迟;
- 系统高可用、容量可扩展、高可运维性;
# 日志系统的格式规范
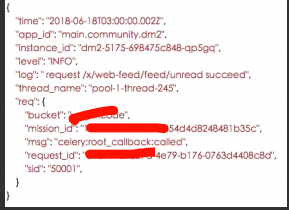
JSON 作为日志的输出格式:
time : 日志产生时间, ISO8601 格式;
level : 日志等级, ERROR 、 WARN 、 INFO 、 DEBUG ;
app_id : 应用 id ,用于标示日志来源;
instance_id : 实例 id ,用于区分同一应用不同实例,即 hostname ;
# 日志系统的设计与实现
日志从产生到可检索,经历几个阶段:
- 生产 & 采集
- 传输 & 切分
- 存储 & 检索
# 采集
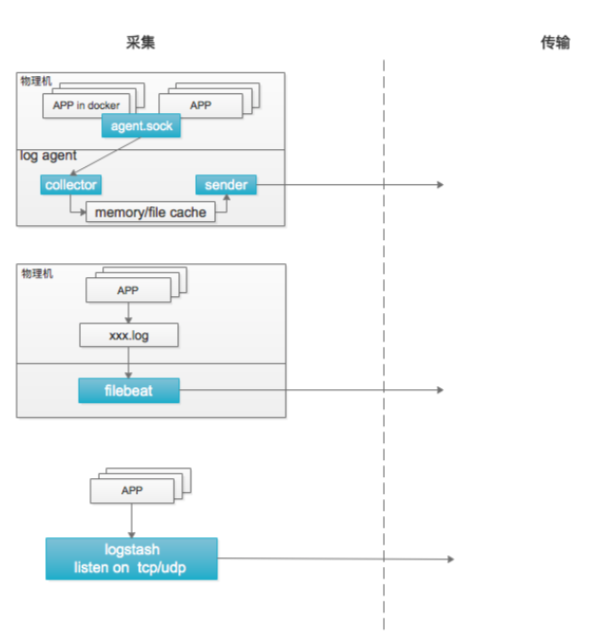
# logstash :
监听 tcp/udp
适用于通过网络上报日志的方式
# filebeat :
直接采集本地生成的日志文件
适用于日志无法定制化输出的应用
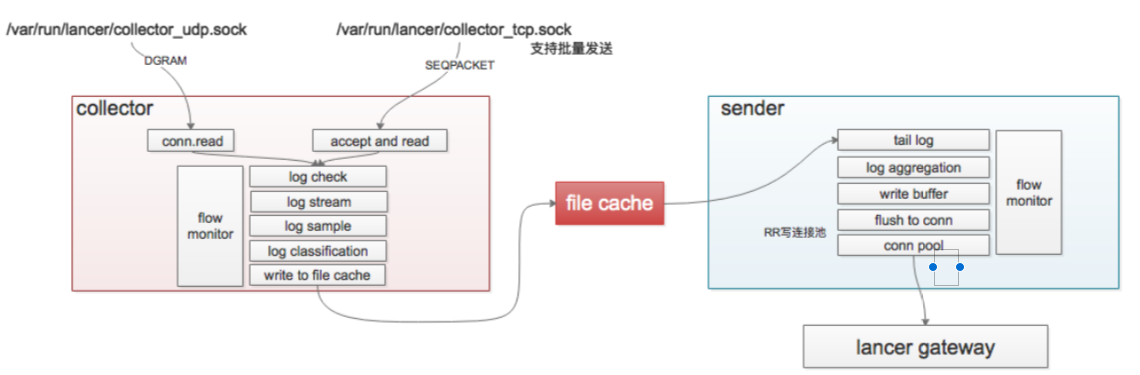
# logagent :
物理机部署,监听 unixsocket
日志系统提供各种语言 SDK
直接读取本地日志文件
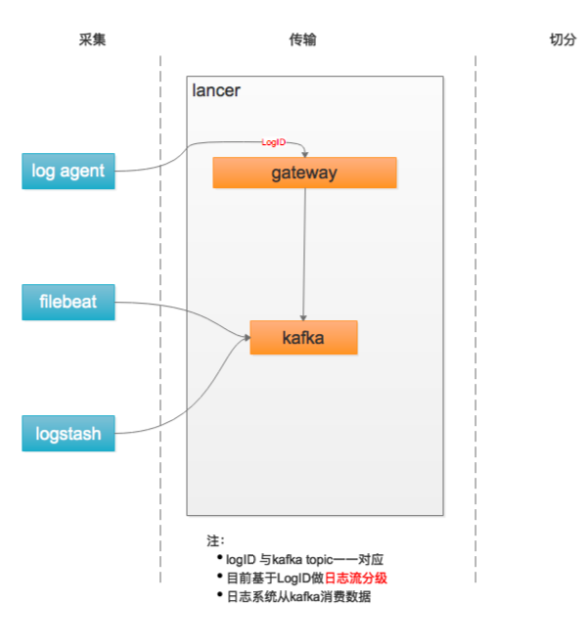
# 传输
基于 flume + Kafka 统一传输平台
基于 LogID 做日志分流:
- 一般级别
- 低级别
- 高级别(
ERROR)
现在替换为 Flink + Kafka 的实现方式。
# 切分
从 kafka 消费日志,解析日志,写入 elasticsearch
bili-index : 自研, golang 开发,逻辑简单,性能 高,可定制化方便。
・日志规范产生的日志 ( log agent 收集)
logstash : es 官方组件,基于 jruby 开发,功能强大, 资源消耗高,性能低。
・处理未按照日志规范产生的日志 ( filebeat 、 logstash 收集),需配置各种日志解析规则。
# 存储和检索
elasticsearch 多集群架构:
日志分级、高可用
单数据集群内:
master node + data node(hot/stale) + client node
每日固定时间进行热 -> 冷迁移
Index 提前一天创建,基于 template 进行 mapping 管理
检索基于 kibana
# 存储 - 文件
- 使用自定义协议,对
SDK质量、版本升级都有比较高的要求,因此我们长期会使用 “本地文件” 的方案实现: - 采集本地日志文件:位置不限,容器内
or物理机 - 配置自描述:不做中心化配置,配置由
app/paas自身提供,agent读取配置并生效 - 日志不重不丢:多级队列,能够稳定地处理日志收集过程中各种异常
- 可监控:实时监控运行状态
- 完善的自我保护机制:限制自身对于宿主机资源的消耗,限制发送速度
# 最后
期望与你一起遇见更好的自己

