
本篇文章是我们【深入一点点】部分第一篇文章,既然我们要 “深入一点点”,那么就剥开 MySQL 的外衣~
先看看 MySQL 的各个 “部位”。
整体来说,MySQL 体系整体分为客户端连接器,服务端,存储引擎三部分。接下来我们就详细的聊聊 MySQL 数据的体系结构这个话题。
本文我们围绕着下面这张图来说。
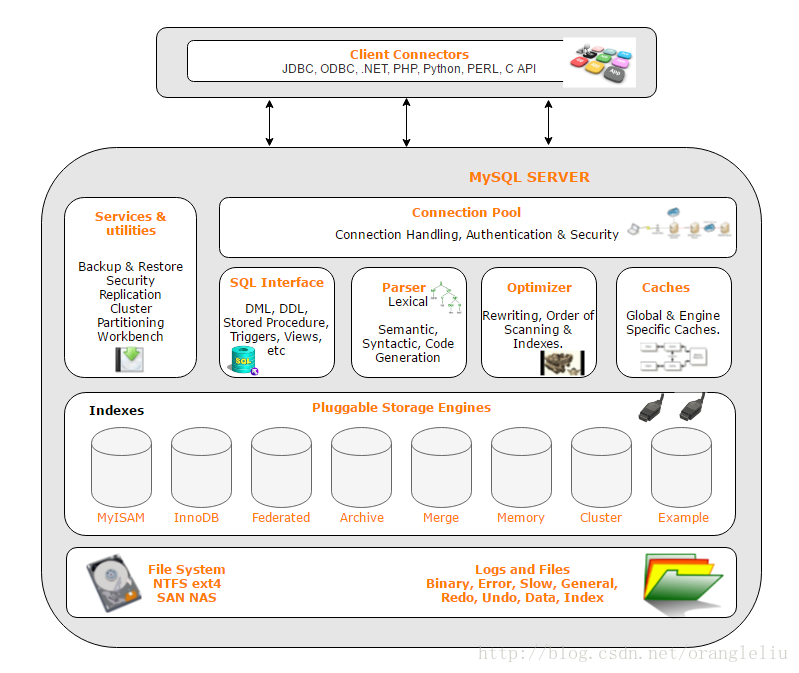
# 客户端连接器
主要的功能是:负责处理客户端的连接请求,与客户端建立连接。比如我们之前写过的 mysql -p 命令和使用 java 连接数据库的程序就是充当这个角色。
# Server 层
# 连接池 (连接器)
如上图中 connect pool 部分所示。
主要是负责管客户端和数据库创建的连接,维持,处理,和用户认证,即用户登录身份的认证和鉴权及安全管理,也就是用户执行操作权限校验。
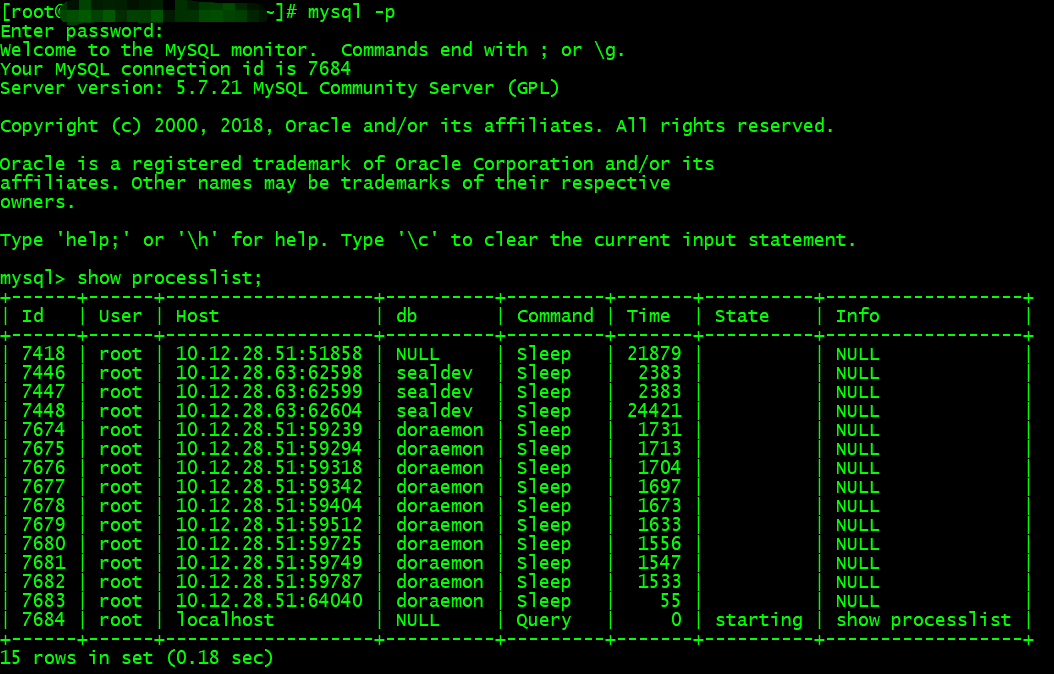
当我们输入 mysql -p 这类命令去连接数据库的时候,输入命令的 shell 是客户端的角色,连接到数据库中组件就是连接器了。
当我输入 mysql -p , 之后,shell 中显示 enter password: 这个就是连接器做出的响应,我们输入密码进入后,可以通过命令: show processlist 来查看连接池中所有的连接。如下图
# 查询缓存 (MySQL8.0 中已经删除了此功能)
图片是老图,在 MySQL8.0 版本中已经删除。所以该部分不做说明
# 解析器 ( parser )
主要负责对 SQL 的语句进行解析,生成解析树。
首先会将 SQL 语句解析成数据库结构,并且将这个数据结构传递到后续的步骤中。如果再解析的过程中发现错误,就直接返回错误结果。
# 优化器 ( Optimizer )
经过了解析器的工作之后, MySQL Server 就知道了你的需求是什么了,优化器的工作就是对需求进行优化,以达到更高的性能要求。
主要的工作是:优化器会根据解析树生成执行计划,并选择合适的索引,然后按照执行计划执行 SQL 语言并与各个存储引擎交互。
比如有一条 SQL : select * from test01_optimizer where id = 1 and value=1;
再执行的时候会有一下两种方案:
- 先对比表中的数据,找到 id=1 的所有数据,然后在这些数据中再去查找所有 value=1 的数据。
- 先对比表中的数据,找到所有 value=2 的所有数据,然后再这些数据中再去查找所有 id=1 的数据。
优化器就是确定使用性能更高一点的方案去执行任务。
# 执行器
通过上一步优化器的工作,得到了该条 SQL 的执行方案,执行器就会按照执行方案去执行查询。
查询执行引擎会根据 SQL 与语句中使用的存储引擎类型,调用不同对应的 API 接口,去与底层存储引擎缓存或者物理文件交互,得到查询结果,并由 MySQL 过滤后,将查询结果返回给客户端。
# 存储引擎层
存储引擎有很多种,比如 InnoDB,MyISAM 等等,后面我们会有一篇文章来介绍存储引擎,这里不多说。
接下来,我们详细的来说下 MySQL 服务器端的各个组件的工作原理。
这篇文章就到这里啦~
明日再见~
# 最后
希望与你一起遇见更好的自己~,一起交流,一起进步

