
在 RocketMQ 架构设计之消息 这篇文章中,我们学习了 消息发送到消费 的整体流程。这篇文章,我们一起来看看 MappedFile 的实现细节.
# 引言
我们都知道的是 RocketMQ消 息都是持久化到磁盘上的,消息的读取和写入也都是会从磁盘上进行 IO 的。可是磁盘的性能不禁另 CPU 啧啧撇嘴。 RocketMQ 是如何实现消息的高性能 IO 的呢?
答案就是 MappedFile 这个 643 行的 java 文件中。
# RokcetMQ 的 MappedFile
我们知道的是 MappedFile 是 RocketMQ 真实消息文件在内存中的映射。主要是通过 java NIO 技术来实现。
我们还是从源码入手,按照 MappedFile 的初始化,提交消息 (消息写入物理内存),刷盘 的顺序去学习。
# 初始化
在 Broker 的初始化过程中, Broker 通过 AllocateMappedFileService 完成了 MappedFile 的 初始化过程。其主要的实现就是在 mmapOperation 方法中。主要的职责有: 1、创建 MappedFile 实例 2、对 MappedFile 进行预热。
# 创建 MappedFile 实例
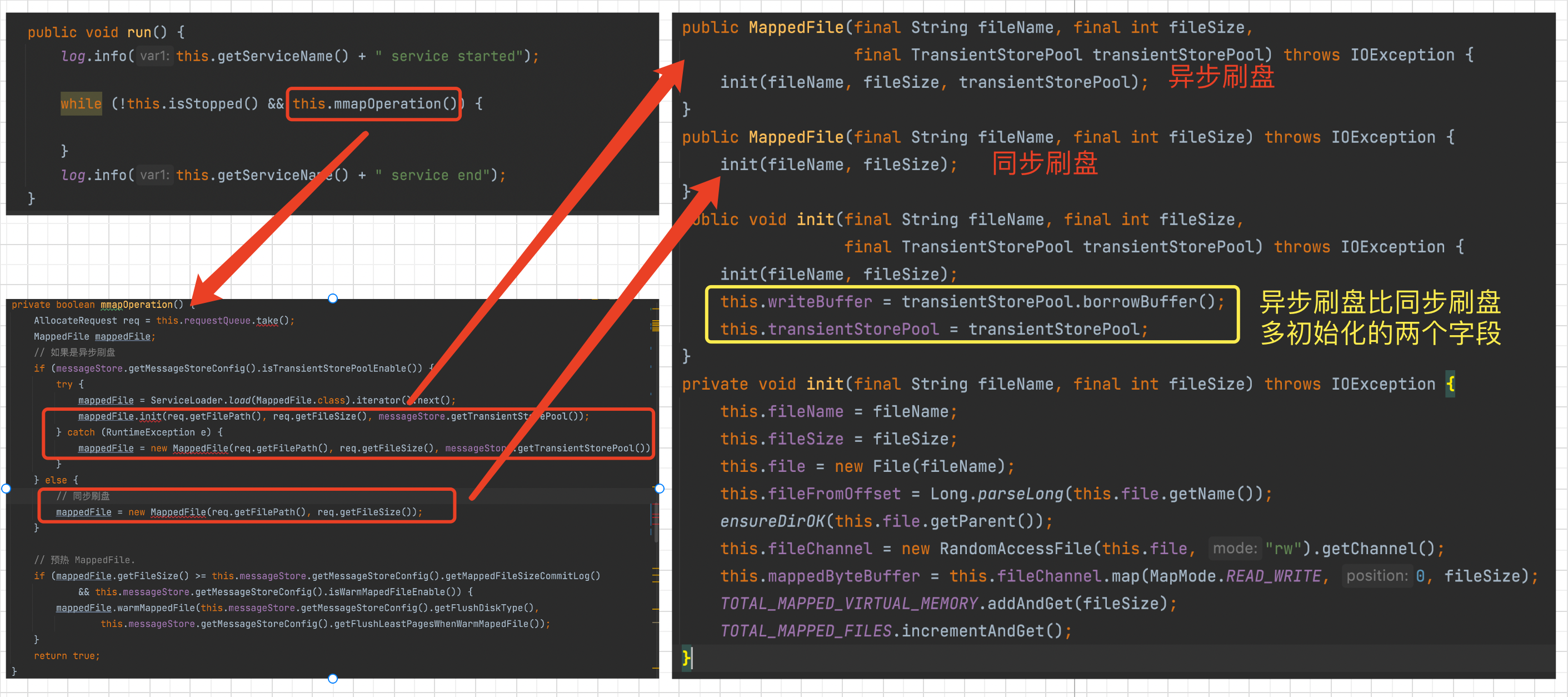
根据 消息的刷盘方式 初始化 MappedFile 实例的不同的字段。 如下图。
# 预热 MappedFile
MappedFile 预热的条件:实际的消息文件大小超过配置的大小 (默认 1G ) 并且 配置允许 MappedFile 预热。
MappedFile 预热的作用是:将 存在在磁盘上的消息预先加载到页缓存中 ( Page Cache ), 这也就是所谓的预热,省去了现用现加载的时间。
预热的主要代码,我贴在下面
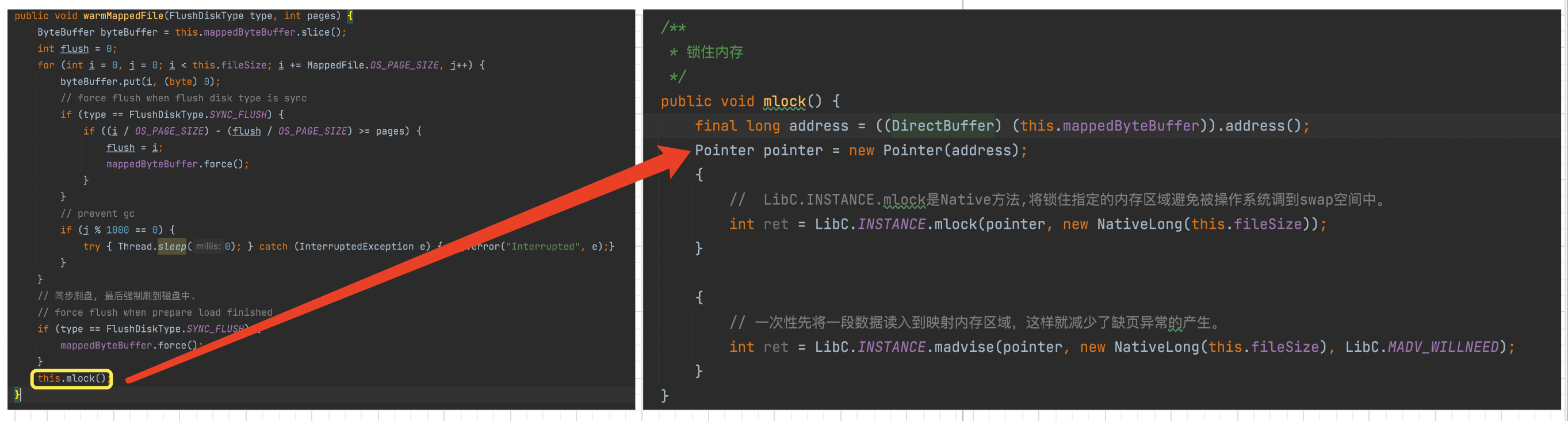
注意看下注释的内容。乍一看好像没有什么奇怪。
我先补充一下关于操作系统中存储的小知识点:
# 页
页是操作系统虚拟内存中空间划分的单位。是逻辑地址空间顺序等分而成的一段逻辑空间,并依次连续编号。页的大小一般为 512B~8KB 。
# 页缓存 (Page Cache)
为了提升对文件的读写效率, Linux 内核会以页大小( 4KB )为单位,将文件划分为多数据块。当用户对文件中的某个数据块进行读写操作时,内核首先会申请一个内存页(称为 页缓存)与文件中的数据块进行绑定。在 Linux 系统中写入数据的时候并不会直接写到硬盘上,而是会先写到 Page Cache 中,并打上 dirty 标识,由内核线程 flusher 定期将被打上 dirty 的页发送给 IO 调度层,最后由 IO 调度决定何时落地到磁盘中,而 Linux 一般会把还没有使用的内存全拿来给 Page Cache 使用。而读的过程也是类似,会先到 Page Cache 中寻找是否有数据,有的话直接返回,如果没有才会到磁盘中去读取并写入 Page Cache 然后再次读取 Page Cache 并返回。而且读的这个过程中操作系统也会有一个预读的操作,你的每一次读取操作系统都会帮你预读出后面一部分数据,而且当你一直在使用预读数据的时候,系统会帮你预读出更多的数据 (最大到 128K )。
page cache 的作用主要是将磁盘中文件缓存到内存,并集中管理,便于回收利用。
了解了 页和页缓存 之后,就应该可以知道了 RocketMQ 为什么会在 MappedByteBuffer 的每个 pageSize 大小的位置 (也就是一个页) 写入一个 0 了。其实就是 把磁盘上的数据写到 PageCache 中,也就达到预热的效果。
还有一个 mlock 方法,这个方法的作用是什么呢?
该方法主要是实现文件预热后,防止把预热过的文件被操作系统调到 swap 空间中。当程序再次读取交换出去的数据的时候会产生缺页异常。 这里也有一个关于操作系统的知识点.
# Page Fault
CPU 通过地址总线可以访问连接在地址总线上的所有外设,包括物理内存、 IO 设备等等,但从 CPU 发出的访问地址并非是这些外设在地址总线上的物理地址,而是一个虚拟地址,由内存管理单元 ( MMU ) 将虚拟地址转换成物理地址再从地址总线上发出,内存管理单元上的这种虚拟地址和物理地址的转换关系是需要创建的,并且内存管理单元还可以设置这个物理页是否可以进行写操作,当没有创建一个虚拟地址到物理地址的映射,或者创建了这样的映射但那个物理页不可写的时候,内存管理单元将会通知 CPU 产生了一个缺页异常。产生了 Page Fault 之后会交给 PageFaultHandler 处理,这里不详细介绍了。导致用户进程产生异常,无法正常工作。
而 mlock 就是为了阻止出现 pageFault 异常
# 内存管理机制:页框回收机制
系统中初识化了很多页缓存,但是这些页长时间没有使用, linux 会有一个 页框的回收机制,将 page cache 中数据标识 “可回收”。 在回收之前,操作系统就会把 Page cache 中的内容复制到 swap cache 中 (这个操作也叫做 swap out ), 如果进程要访问 当前页的时候,就会出现 page Fault . 然后 根据 swap cache 内存地址把内存拷贝到新的 PageCache 中 (这个操作叫做 swap in ).
# 总结:预热 MappedFile
预热时已经已经建立了 MappedByteBuffer 和物理内存的地址映射,但是还没有把消息加载进内存,所谓的预热是为了把消息读取到操作系统的物理内存中。并且使用 mlock 把锁定内存,防止消息被操作系统回收。
# 消息写入物理内存
这篇文章《RocketMQ 架构设计之消息》我们介绍了消息写入的大致过程: Broker 的 Netty Server 接收到 Producer 发送来的消息,通过 SendMessageProcessor 进行处理,然后 DefaultMessageStore 把消息交给 CommitLog 进行写消息和刷盘.
我们都知道的是 CommitLog 表示的是 RocketMQ 的消息文件。它提供了写入消息和读取消息的功能。我们就从 CommitLog . asyncPutMessage 来看消息的写入过程。
asyncPutMessage 这个方法 实现了两个功能:
- 通过
ByteBuffer写入消息。 - 提交刷盘请求。
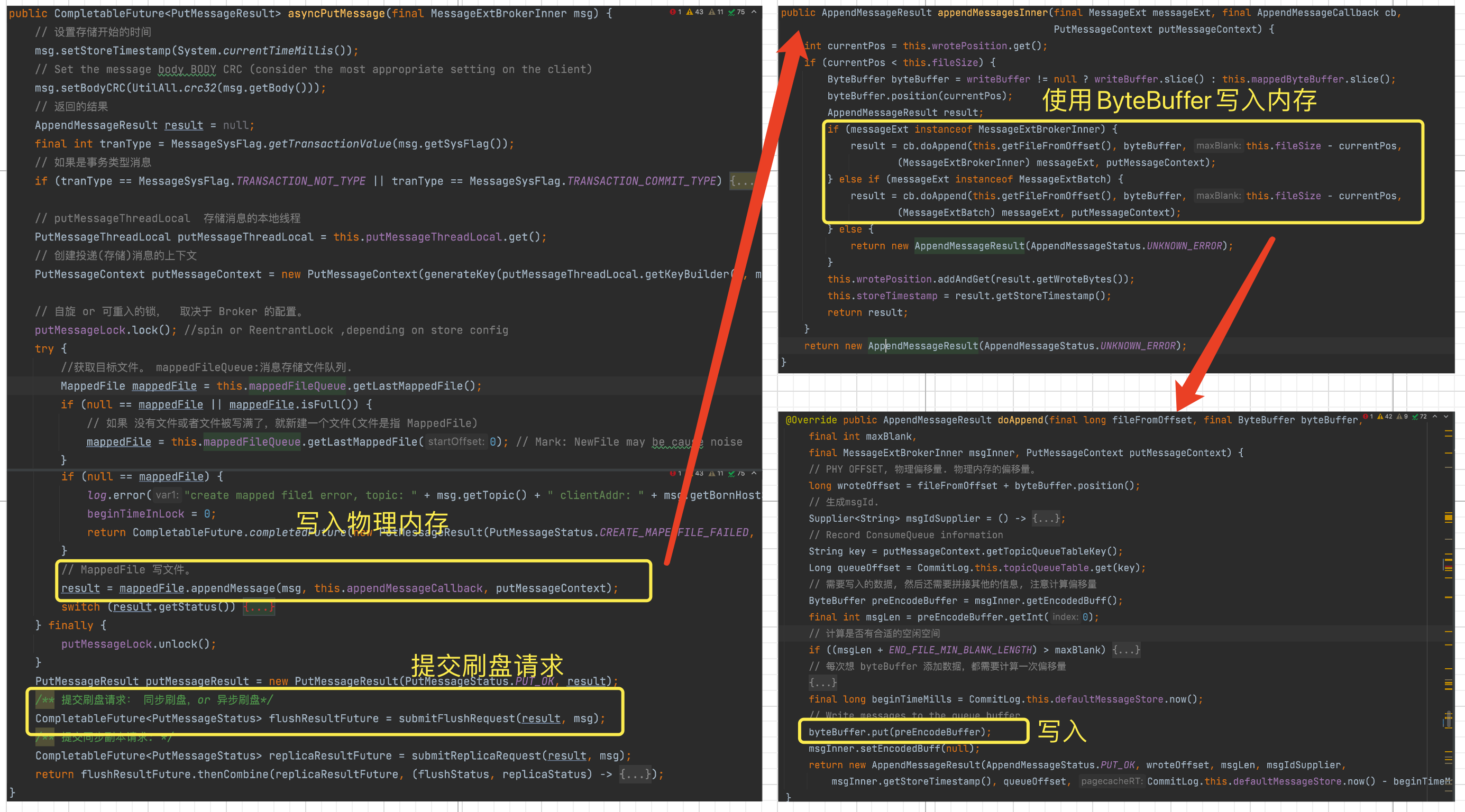
上图源码中可以看到 CommitLog 调用了 MappedFile 把消息写入文件,真实去写入者是 ByteBuffer.put() 方法把消息写到了物理内存中.
注意,这个 ByteBuffer 非常的有意思.
当 刷盘方式是 同步刷盘的时候,使用的是: this.mappedByteBuffer.slice() , 这个 mappedByteBuffer 对象是有 FileChannel.map() 方法生成。
当刷盘方式是 异步刷盘的时候,则是使用 DirectByteBuffer 进行写入的。
这两者有什么区别呢?本质上其实没有什么区别!!
FileChannel.map() 出来的 MappedByteBuffer 类型是一个抽象类,本质上还是通过 DirectByteBuffer 进行构建出来的。
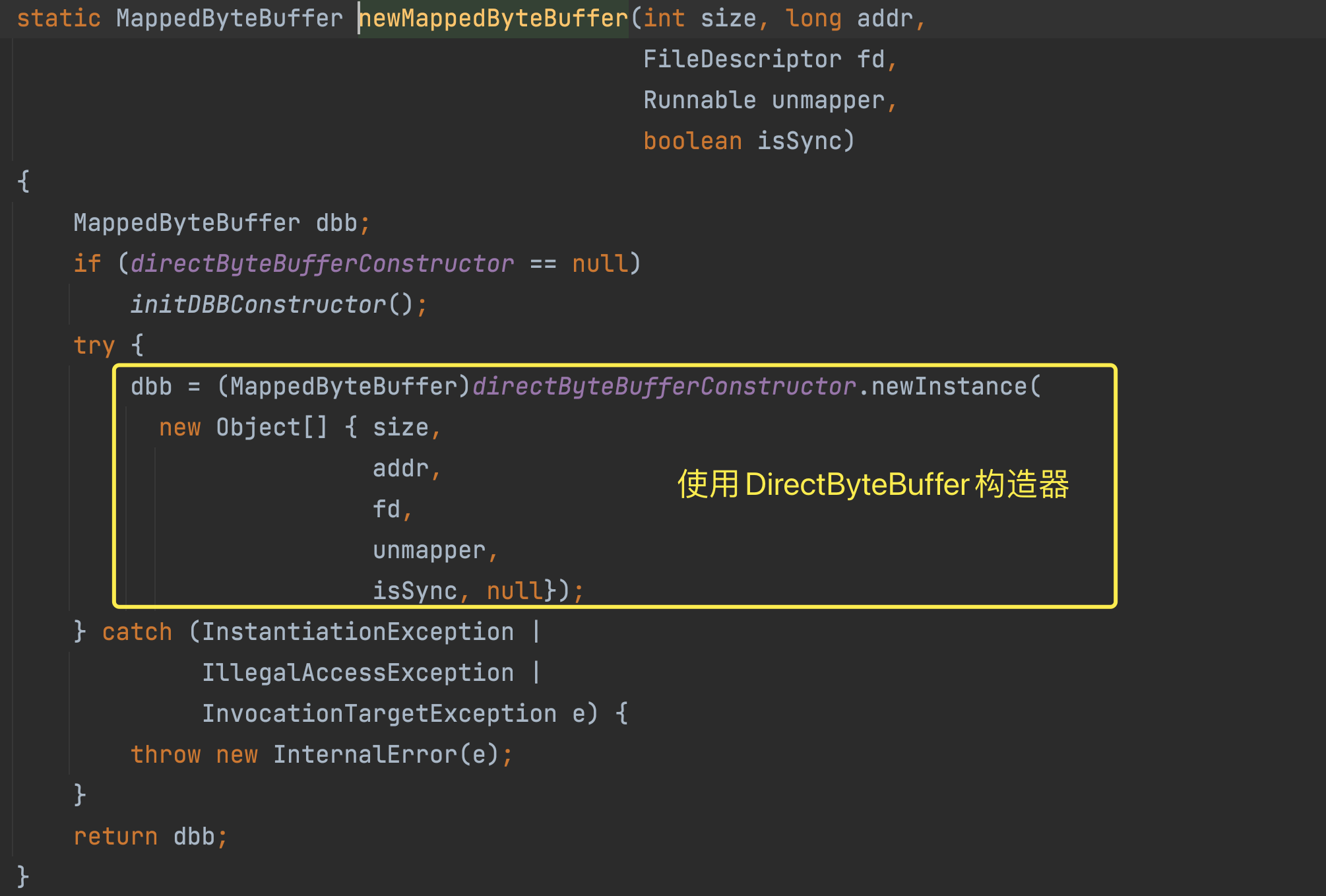
这样, RocketMQ 就把消息写入到了物理内存中.
什么时候把消息写到磁盘上的呢?
我们读写的数据都是从 pageCache 中读写的,并不会直接读写磁盘。
操作系统中提供了两种方式来实现 pageCache 和 磁盘的数据一致性。
Write Through(写穿):向用户层提供特定接口,应用程序可主动调用接口来保证文件一致性;Write back(写回):系统中存在定期任务(表现形式为内核线程),周期性地同步文件系统中文件脏数据块,这是默认的Linux一致性方案.
所以,我们接下来看 RocketMQ 是如何确保消息落盘的。
# 消息刷盘
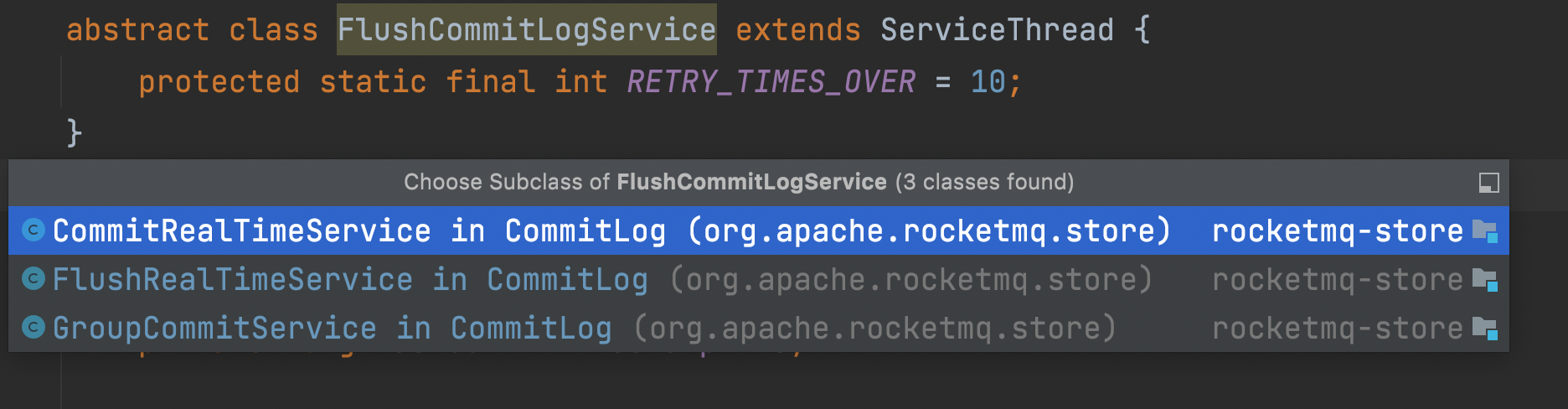
RocketMQ 有三种刷盘方式。两种刷盘的实现。
分别是 GroupCommitService (同步刷盘), FlushRealTimeService (异步刷盘), CommitRealTimeService (异步刷盘 + 缓冲区). 这三个类有一个共同的父类:
我们详细的去看一下同步刷盘的过程。因为异步刷盘和同步刷盘的 flush 过程是一样的.
# 同步刷盘
在消息启动的时候,如果配置了 使用同步刷盘方式的话, Broker 会启动 GroupCommitService 和 CommitRealTimeService (这个是异步刷盘并且配置内存池的时候使用的刷盘方式,不管配置什么方式的时候都会创建,在启用 isTransientStorePoolEnable 的时候才会 start() ).
GroupCommitService 在启动之后,会每 10ms 执行一次刷盘操作。
我们从 CommitLog 添加完消息提交刷盘请求开始,详细分析整个过程.
如下图。
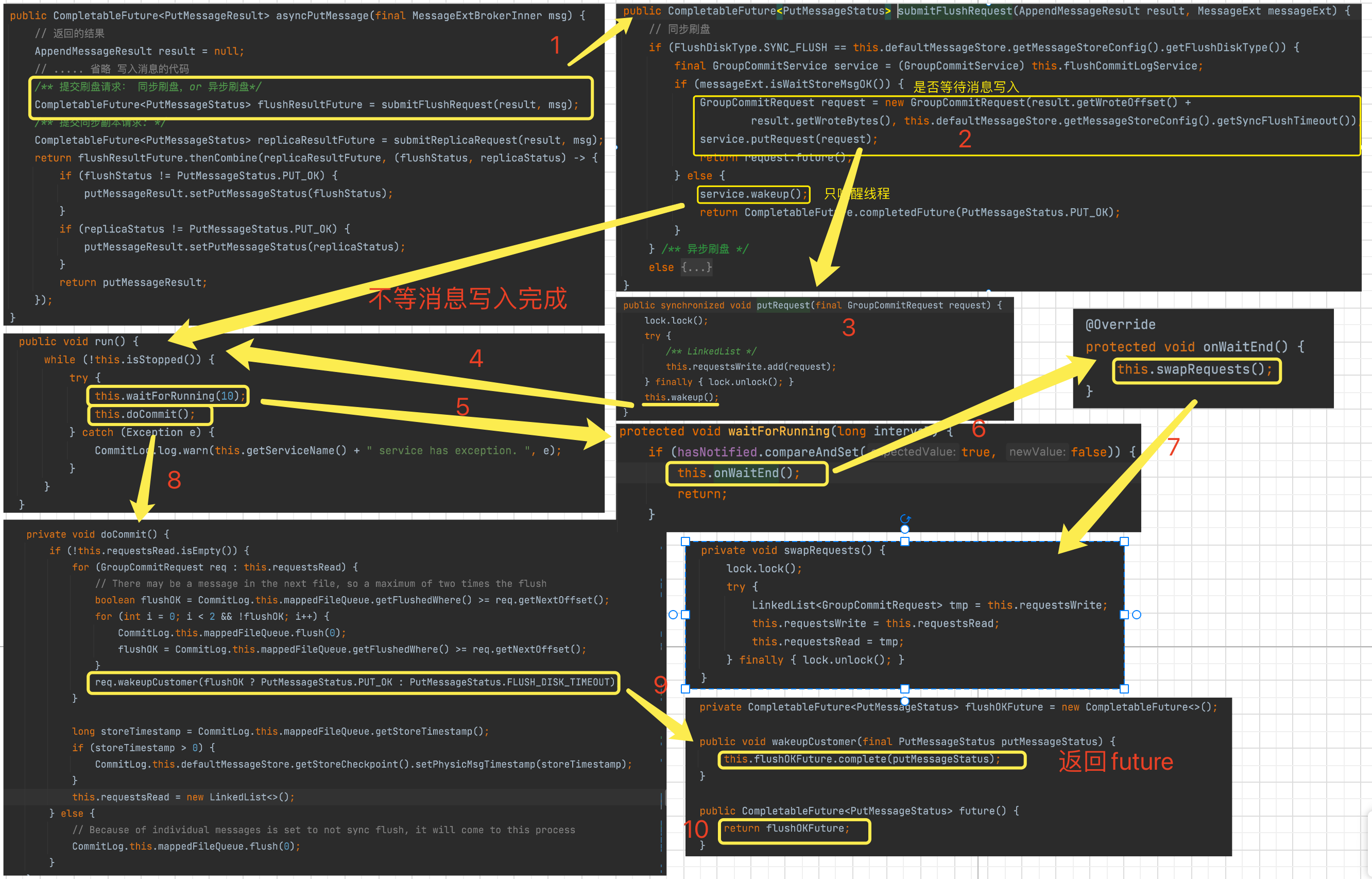
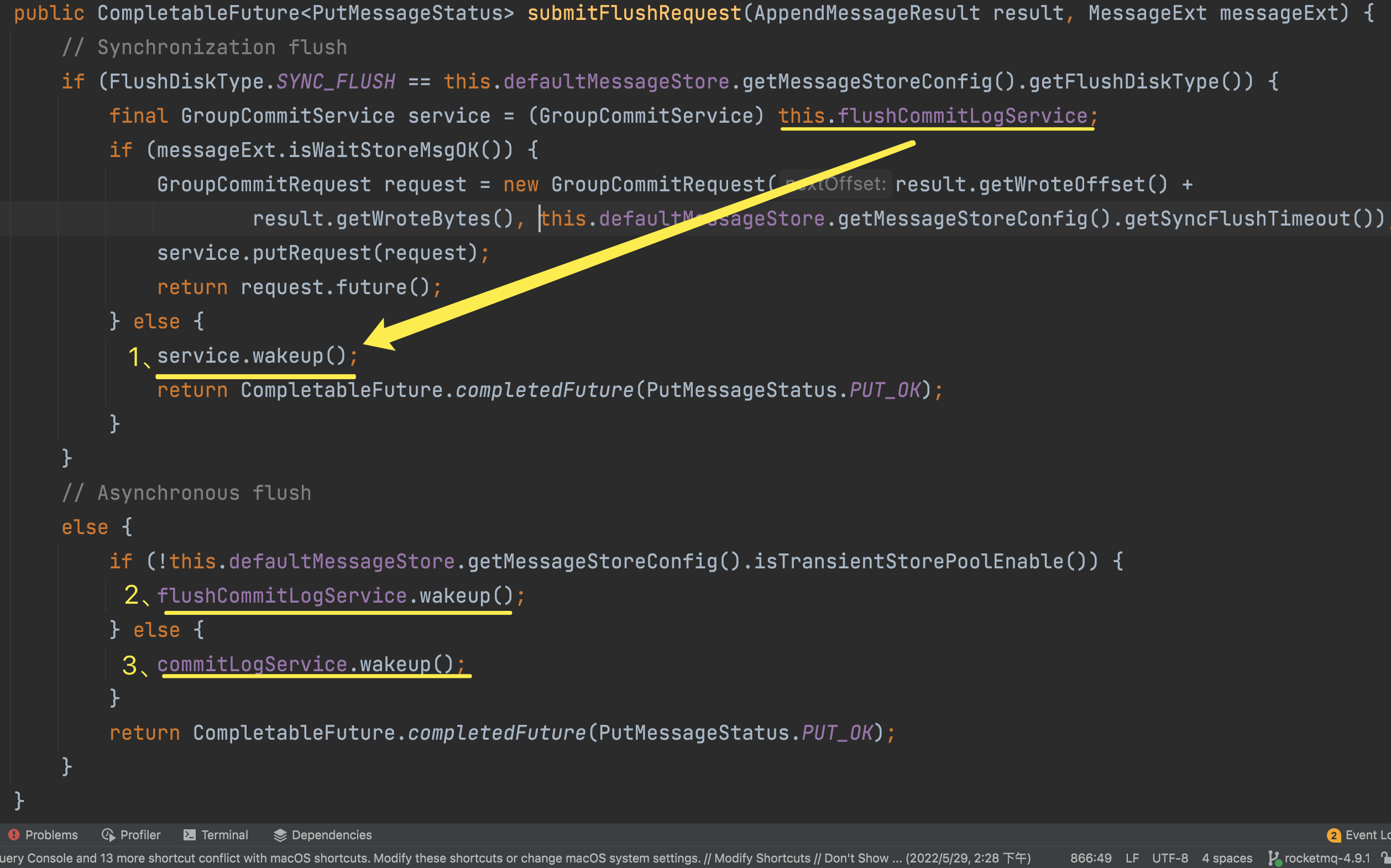
CommitLog 提交一个 刷盘请求,这时根据配置 是否等待消息写入完成 来执行刷盘操作.
- 如果不等待消息写入完成,则唤醒
GroupCommitService, 直接返回写入成功,这时 线程是否执行是由JVM决定的,所以并不确定线程立刻就执行了。 - 如果等待消息写入完成,即第二步,则会放入一个
GroupCommitRequest同步刷盘请求。实际上是把 这个Request放到GroupCommitService的LinkedList中,为了线程安全和提高效率,使用了两个LinkedList, 分别是write和read. 当执行刷盘操作的时候,会将write和read互换。每次都会读取read队列中的Request进行刷盘。这一步是在waitForRunning方法中执行的,见如图第5-7步。
接下来就是刷盘操作了,调用mappedFileQueue.flush(0)操作完成刷盘动作。然后,返回CompleteFuture如图中第 9 步。 当需要等待消息写入完成的时候,CommitLog添加消息是在一直等待的。如下图.
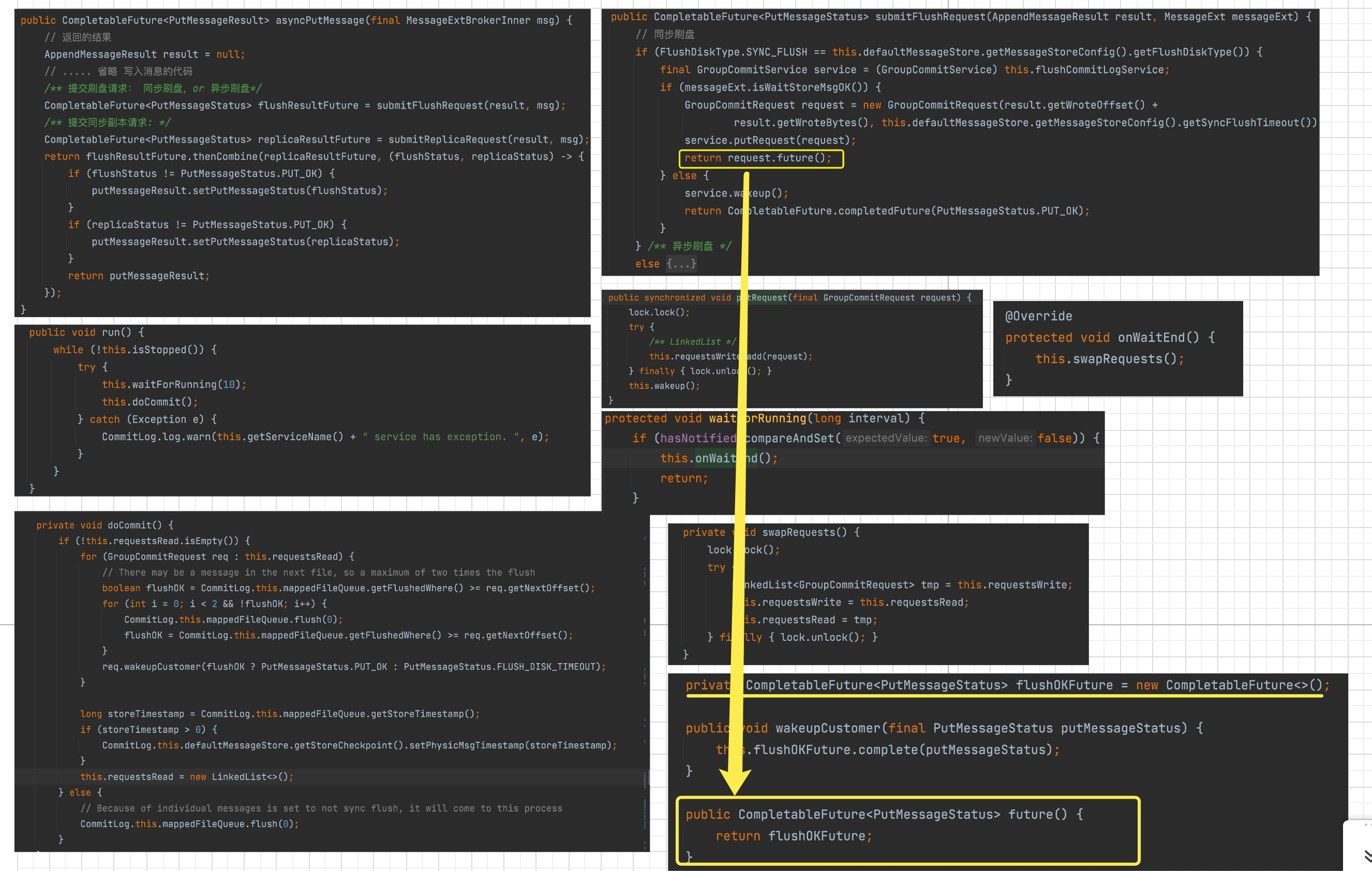
那接下来,我就详细的来看下 mappedFileQueue 其实是 MappedFile 的刷盘过程.
# MappedFileQueue.flush
1 | /** |
获取到当前需要写入的 MappedFile . 然后通过 MappedFile 写入 "磁盘"。
1 | /** |
# 异步刷盘
看完同步刷盘的流程之后,异步刷盘就简单很多了。
异步刷盘仍然是使用 mappedFileQueue.flush() 进行刷盘的
实现逻辑如下图 (代码有精简):
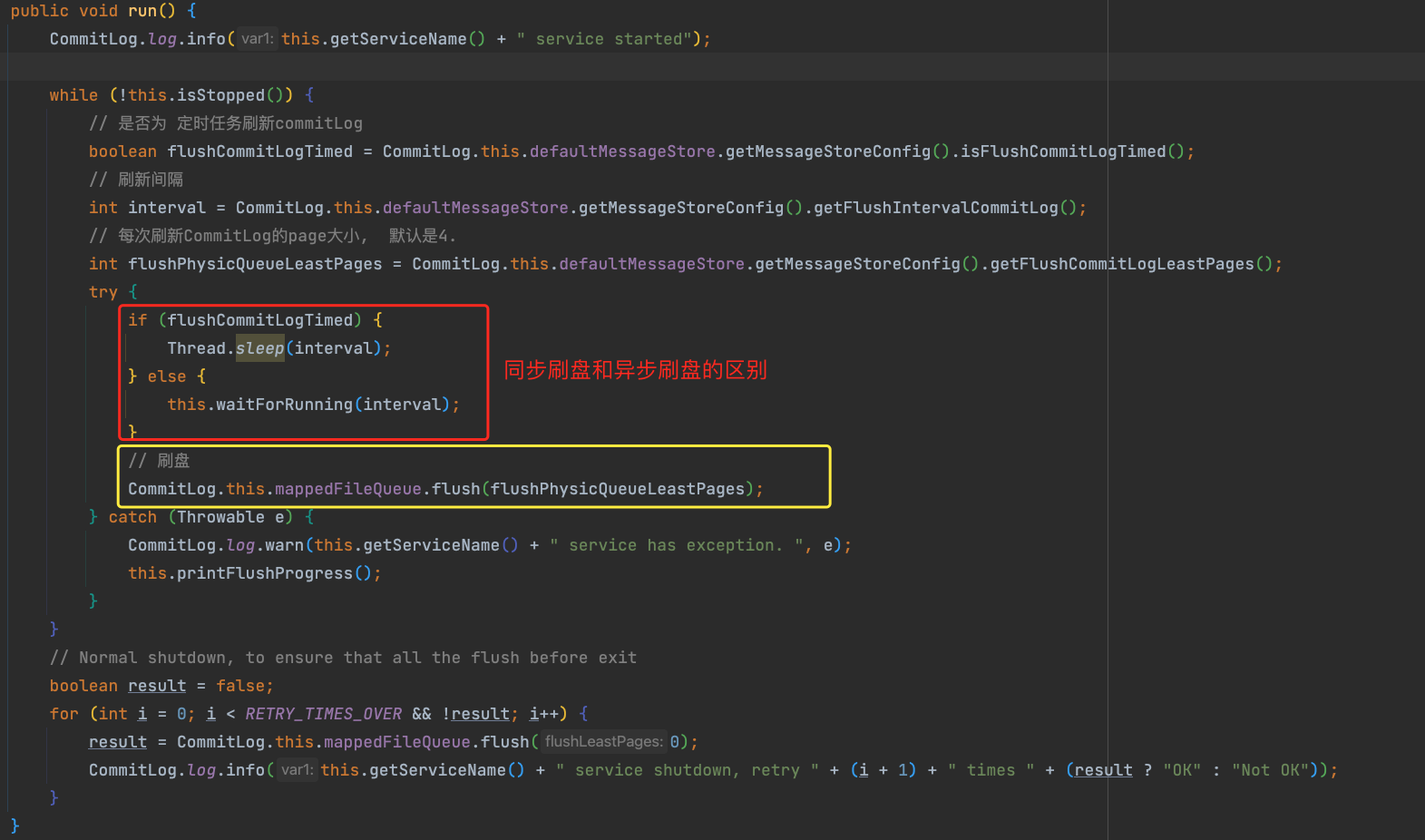
可以看到,异步刷盘的线程在执行的时候,会通过 Thread.sleep() 进行线程等待 或者 通过 CountDownLatch2 进行等待的。需要注意的是: CountDownLatch2 是 RocketMQ 实现的一个类,作用同 CountDownLatch 一样。
而且在 消息进行刷盘的时候, 只需要将 FlushRealTimeService 线程 wakeup() 就好了。
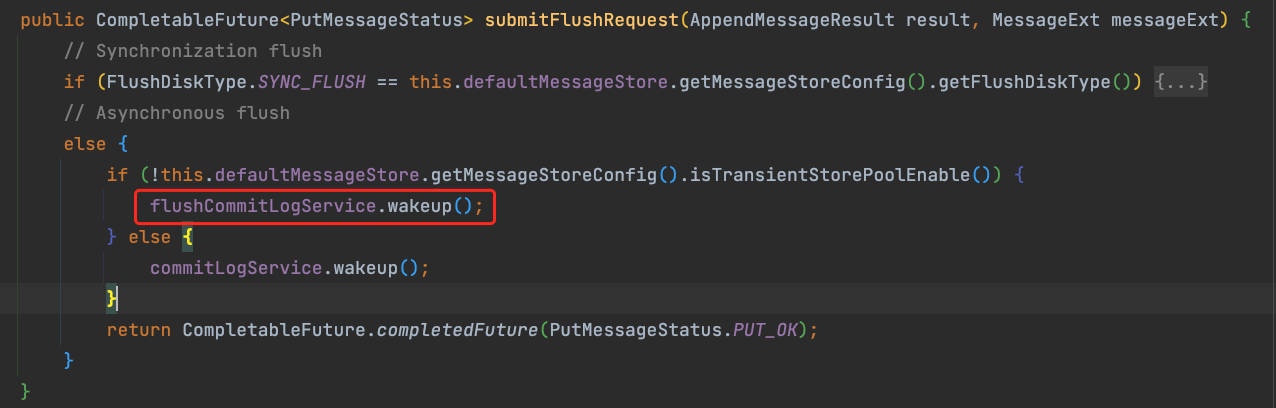
此时的 flushCommitLogService 是 FlushRealTimeService 的实例。
异步刷盘的时机:
- 判断是否超过
10s没有刷盘了,如果超过则强制刷盘。 - 等待
flush间隔,默认500ms - 通过
MappedFile刷盘 - 超过
500ms的刷盘日志 Broker正常挺值钱,把内存page中的数据刷盘。
和同步刷盘相比,异步刷盘提高了 IO 性能。
# 异步刷盘 + 缓冲区
我们先看一下执行的流程。
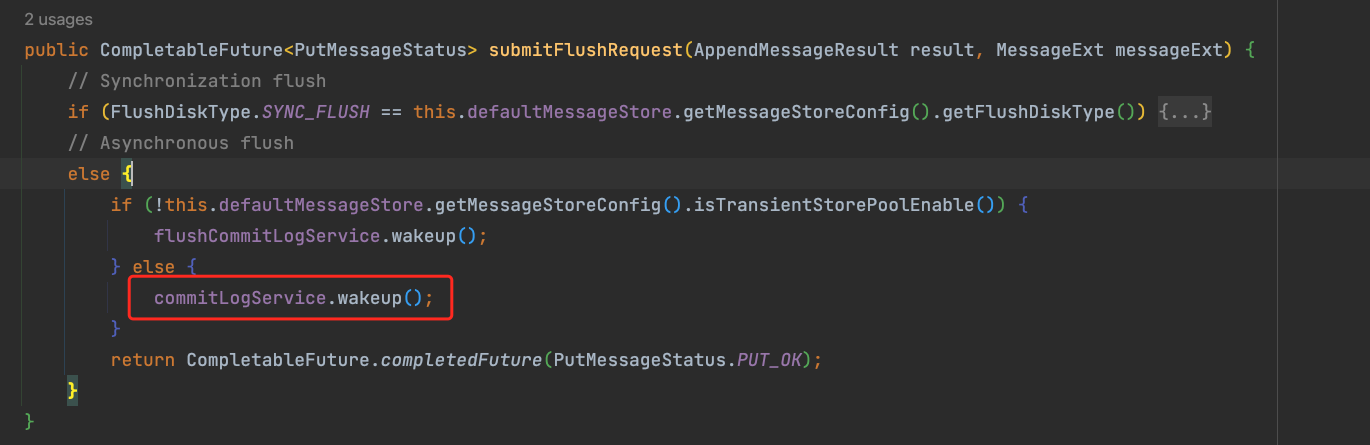
然后如果是 CountDownLatch2 结束,执行线程的话,就会执行下面的逻辑:
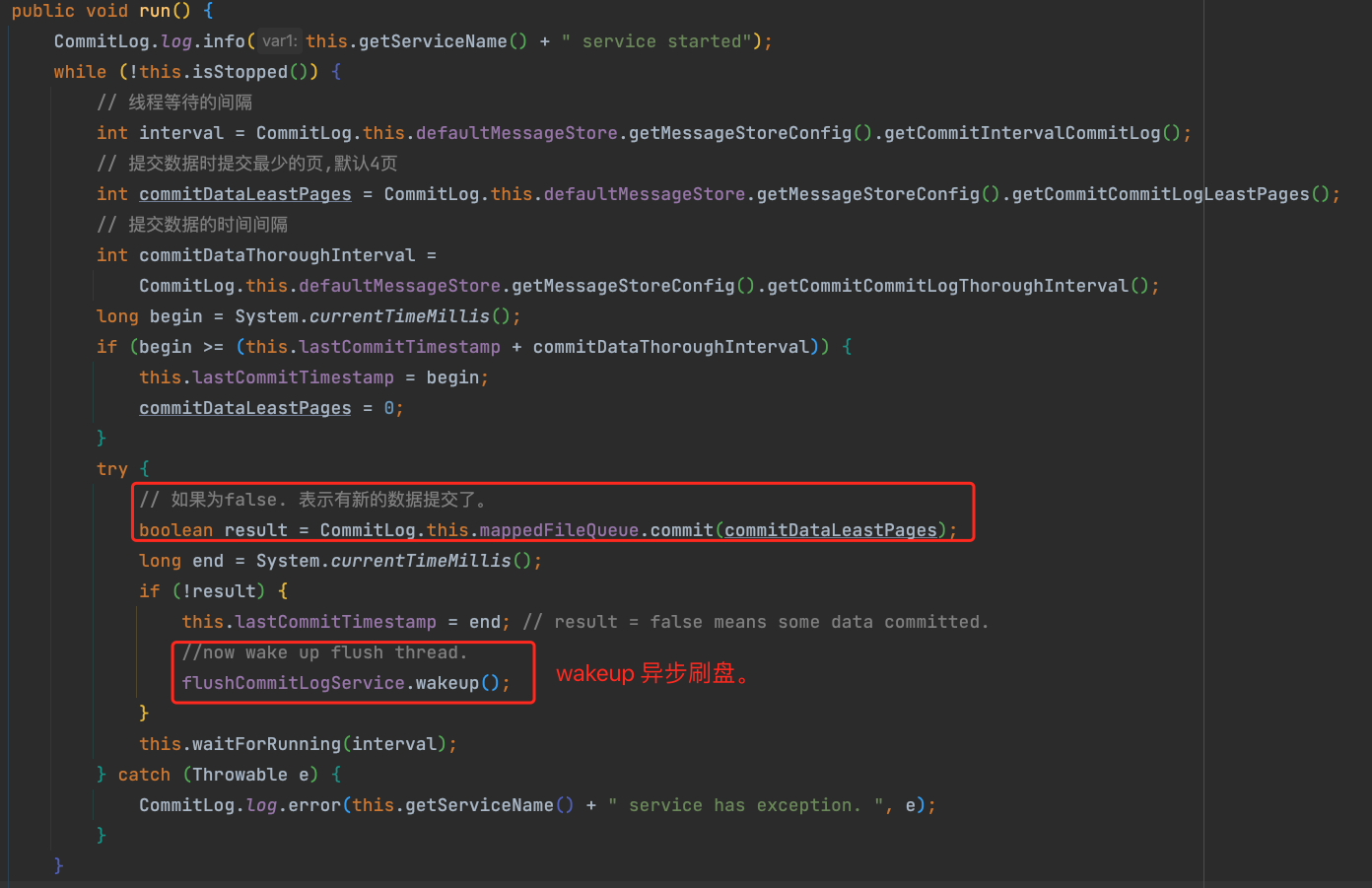
判断是否有新的数据提交, 如果有,则唤醒异步刷盘方式。没有则等待。
waitForRunning 方法的逻辑是:
可以看到 是通过线程等待的方式,等待时间间隔完成。
开启缓冲区后的刷盘策略:
- 判断是否超过
200毫秒没提交,需要强制提交 - 提交到
MappedFile,此时还未刷盘 - 然后唤醒刷盘线程
- 在
Broker正常停止前,提交内存page中的数据
RocketMQ 申请一块和 CommitLog 文件大小相同的堆外内存在做缓冲区,数据会先写入缓冲池,提交线程 commitRealTimeService 每隔 500ms 尝试提交到 FileChannel 中进行刷盘,最后使用 FlushRealTimeService 来完成。
使用了缓冲区的目的是 多条数据合并写入,提高 IO 性能.
# 总结
RocketMQ 使用 FileChannel 和 MappedByteBuffer 完成了消息的落盘。提供了三种持久化策略:
- 同步刷盘:使用
GroupCommitService线程,通过MappedByteBuffer的force方法将消息写入文件中,写入完成后才会返回ACK. - 异步刷盘:消息写入
pageCache之后,就立即返回ACK. 使用FlushRealTimeService线程 通过FileChannel的force方法确保将消息写入文件. - 异步刷盘 + 开启缓冲区:
RocketMQ申请一块直接内存用作数据缓冲区,消息先写入缓冲区,然后由CommitRealTimeService线程定时将缓冲区数据写入FileChannel,再唤醒FlushRealTimeService将FileChannel缓冲区数据强制刷新到磁盘。
回答一下文章开头的问题:
RocketMQ 是如何提高 数据读写的性能的呢?
RocketMQ 的大致做法是,将数据文件映射到 OS 的虚拟内存中(通过 JDK NIO 的 MappedByteBuffer ),写消息的时候首先写入 PageCache ,并通过异步刷盘的方式将消息批量的做持久化(同时也支持同步刷盘);订阅消费消息时(对 CommitLog 操作是随机读取),由于 PageCache 的局部性热点原理且整体情况下还是从旧到新的有序读,因此大部分情况下消息还是可以直接从 Page Cache ( cache hit )中读取,不会产生太多的缺页( Page Fault )中断而从磁盘读取。当然, PageCache 机制也不是完全无缺点的,当遇到 OS 进行脏页回写,内存回收,内存 swap 等情况时,就会引起较大的消息读写延迟。对于这些情况, RocketMQ 采用了多种优化技术,比如内存预分配,文件预热, mlock 系统调用等,来保证在最大可能地发挥 PageCache 机制优点的同时,尽可能地减少其缺点带来的消息读写延迟.
# 最后
期望和你一起遇见更好的自己

