
之前我们已经学习了 RocketMQ 是由四个部分组成的。这篇文章更加深入的来看看这个四个部分。
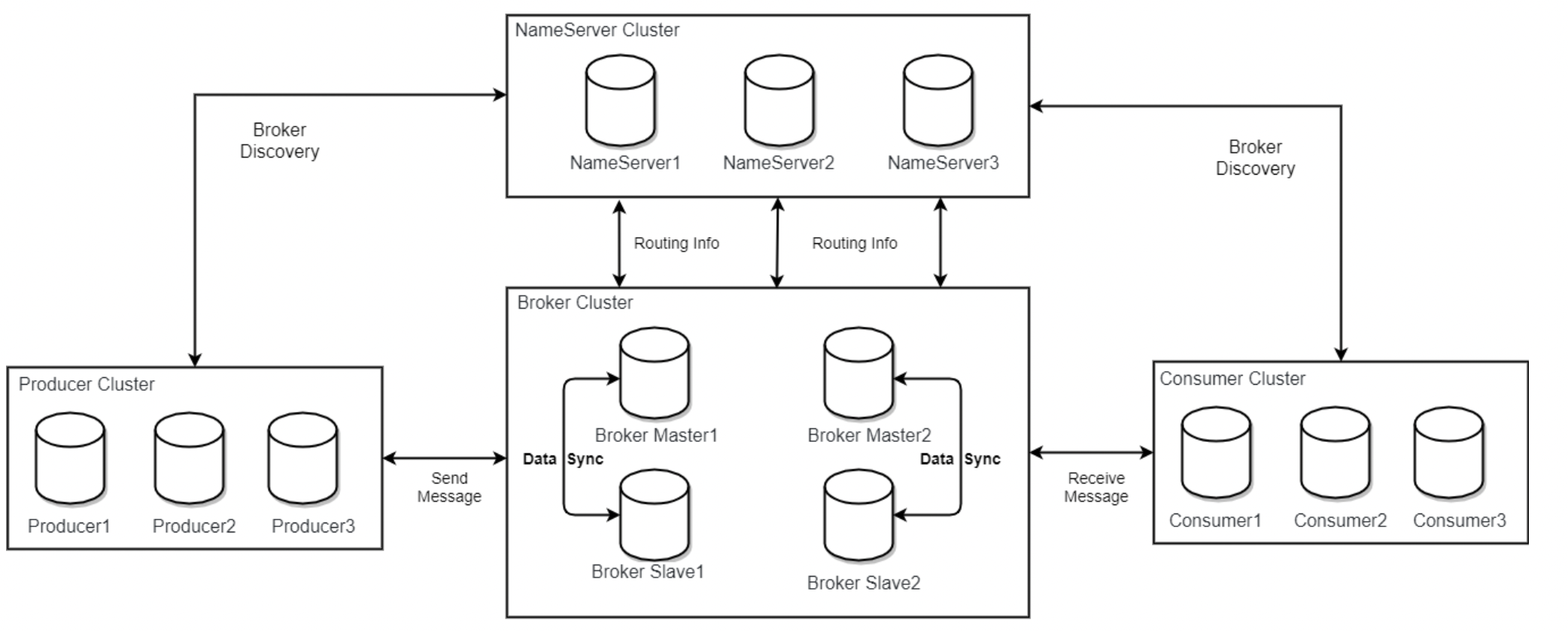
# NameServer
接下来,我们来看 NameServer 的相关内容,我们都知道 NameServer 是 RocketMQ 的注册中心。那它肯定会有 服务发现,检查检查,路由等等功能, 我们就按照这个思路去看看 NameServer 是如何启动的。
# NameSrv 的启动过程
我们在部署 RocketMQ 的时候,使用下面的命令启动了 RocketMQ 的 NameServer .
1 | nohup sh mqnamesrv & |
这条命令其实执行的是:
1 | sh ${ROCKETMQ_HOME}/bin/runserver.sh org.apache.rocketmq.namesrv.NamesrvStartup $@ |
也就说,这条命令执行运行的 NamesrvStartup 类。
NameSrv 的启动其实就两步:
- 封装配置参数: 根据命令行参数封装
NameSrvConfig配置。 可以执行配置文件,会解析配置文件中的相关配置。 - 初始化并启动
NamesrvController.- 初始化:
- 对
NameSrvController进行配置, - 创建远程
netty Server, - 注册
DefaultRequestProcessor,处理各种连接请求, - 创建了两个定时任务:每
10s扫描一次Broker列表,移除不存活的Broker。每10s打印一次配置属性。 - 创建配置文件监听器,监听配置文件是否有变化。
- 对
- 启动:
- 启动
netty Server: 实际上启动一个 Netty 服务。 - 启动文件监听器。
- 启动
- 初始化:
在启动过程中, Broker 的健康检测是通过定时任务来实现的。那路由功能是怎么实现的呢?
这就要看 在 NameServer 中最重要的一个类了: DefaultRequetProcessor . DefaultRequestProcessor 封装了各种连接请求的处理。比如 Broker 的注册,根据 Topic 获取路由信息等等。具体可以参考如下代码:
1 |
|
这段代码里实现了所有的 Broker , Producer , Customer 和 NameServer 交互的处理逻辑,包括路由功能等等。
# NameServer 的关闭
NameServer 的关闭就非常简单了.
NameSrvStartUp 在 initialize 和 start 之间,加入了 一个 关闭事件的监听器.
1 | // 添加关闭的回调。 |
内部是使用 NameSrvController 的 shutdown 方法。
主要进行:
- 关闭
Netty服务 - 关闭线程池
- 关闭
scheduledExecutorService - 关闭文件监听器
# Broker
Broker的启动过程Broker怎么样进行消息存储的Broker的内部运行原理是什么样的?- 关闭流程
在 RocketMQ 的 Broker 这个启动环节下,我们可以直接找到 BrokerStartUp.java 这个类。
# Broker 的启动过程
Broker 的启动本质上是启动了 一个 Netty 服务端和一个 Netty 客户端。 使用 Netty 客户端完成向 NameSrv 的注册,心跳检测,等数据交互。 使用 Netty 服务端处理 Producer 发送的消息,并将消息按照不同的消息类型存储下来。
首先 Broker 依然还是会加载 Broker 的相关配置,包括:a. 命令行中指定的参数,比如 mqbroker ,-c 等, b. -c 指定的文件中的 Broker 属性。然后根据加载的 NettyServerConfig (启动的 Netty 服务端的配置), NettyClientConfig (启动的 Netty 客户端的配置), BrokerConfig ( Broker 的配置), messageStoreConfig (存储消息的配置) 创建 BrokerController . 之后及时初始化 BrokerController ,注册 Shutdown 回调。最后启动 BrokerController 。 shutdown 回调其实没有什么可说的。我们再简单的看看初始化过程。
# 初始化过程
初始化过程是一个 "漫长" 的过程。一开始是在去加载一些数据,初始化会去加载 创建的 topic 数据,消息的消费偏移量,广播组,消费过滤数据等的数据,然后创建 MessageStore 对象,作用是存储消息。注意这个 MessageStore 是支持插件的形式扩展的。 如果数据加载成功之后,就会启动 netty 服务端。 代码中 启动了两个 netty 服务端: remotingServer 和 fastRemotingServer 。然后就是初始化了一些线程池 用于注册 Processor 。 在注册 Processor 的过程中,可以看到 fastRemotingServer 和 remotingServer 除了端口不一样之外, fastRemotingServer 没有 注册 PullMessageProcessor . 也就是说 fastRemotingServer 不支持 pullMessage 请求。然后 BrokerController 创建很多的定时任务,比如:定时记录每天的消息数据,定时持久化消费者消息。定时持久化 消费者过滤时的数据情况 等。再就是 更新 Broker 的 NameServer 地址。 最后初始化事务,初始化权限,初始化 RPC 钩子。
# 启动过程
在完了初识话之后,下一步就是启动了。和 NameServer 一样的流程,先初始化,在 start . 启动过程分为以下几步:
- 启动
messageStore - 启动
remotingServer - 启动
fastRemotingServer - 启动文件监听器
- 启动
BrokerOutAPI, 向NameServer服务端发送相关请求的连接与断开等,定时扫描ResponseTable并触发回调。 - 启动
PullRequestHoldService: 存储pull Message的请求,并触发执行pull Message. - 启动定时任务,定时扫描不存活的生产者,消费者,消息过滤服务 (非
tag过滤)。 - 启动消息过滤服务。 消息过滤服务并非是基于
tag的消息的过滤,而是在Broker端提供了一种更加细粒度的消息过滤控制。 Broker的容灾处理- 定时任务:注册
Broker到NameServer - 启动
broker统计,无动作 - 清理过期请求。
# 关闭过程
这个关闭流程这里就不多说了,就是把上面启动的过程挨个关闭就好了。具体细节可以参考 org.apache.rocketmq.broker.BrokerController#shutdown() 我们后面也会分析这部分的代码。 除了关闭上面启动的服务之外,在关闭的时候,需要将消息进行持久化。 比如 ConsumerOffset , ConsumerFilter , 这也是当服务再次启动时保证消息能够正常被消费的保障。
# Producer
消息发布的角色,支持分布式集群方式部署。 Producer 通过 MQ 的负载均衡模块选择相应的 Broker 集群队列进行消息投递,投递的过程支持快速失败并且低延迟。
我们从最简单的一个示例来看,生产者的启动流程
1 | // 使用GroupName初始化Producer |
关于 生产者角色,我们应该了解什么?或者说,看到上面的代码,你想更深入的知道些什么吗?(我听到了你说,不想…)
- 生产者是如何启动?启动过程中生产者都做了哪些事情?
- 生产者是如何和
Namesrv进行交互的?交互是什么信息?生产者是如何和NameSrv进行健康检查的? - 生产者是怎么样发送消息的?发送消息的过程是什么样的?
- 生产者的关闭流程是什么样的?
# 生产者启动流程
# 封装生产者的属性
1 | DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name"); |
我们可以通过 DefaultMQProducer 类创建一个生产者对象。 这个类我们打算发送消息的程序入口。需要注意的是:这个类的实例是线程安全的:在配置并启动进程后,该类可以被视为线程安全的,可以在多个线程上下文中使用。
DefaultMQProducer 提供了 5 个构造参数 ( 4.9.1 版本,并非在一个构造方式中)。
String namespace: 生产者实例的命名空间。可以理解为 MQ 生产者的名称。String producerGroup: 生产者组。 生产者组在概念上聚合了完全相同角色的生产者实例。 这对事务消息非常重要。对非事务性消息就没有太大关系了。(=> 小白说:一类生产者。)RPCHook rpcHook: 每个远程命令执行要执行的 RPC 回调。RPCHook 是一个接口,提供了两个方法 doBeforeRequest 和 doAfterResponse,表示在执行请求之前和接收返回之后分别执行相关逻辑;boolean enableMsgTrace: 是否开启消息追踪String customizedTraceTopic: 消息追踪日志使用的队列名字String nameSrvAddr: 这个字段没有在构造方法中,我们可以手动调用 set 方法进行设置,也可以通过系统变量的形式进行设置。
生产者在设置完对应的参数之后,就会调用 Start() 方法。 start 方法会设置 group , 然后调用在 构造方法中初始化的 defaultMQProducerImpl 实例。
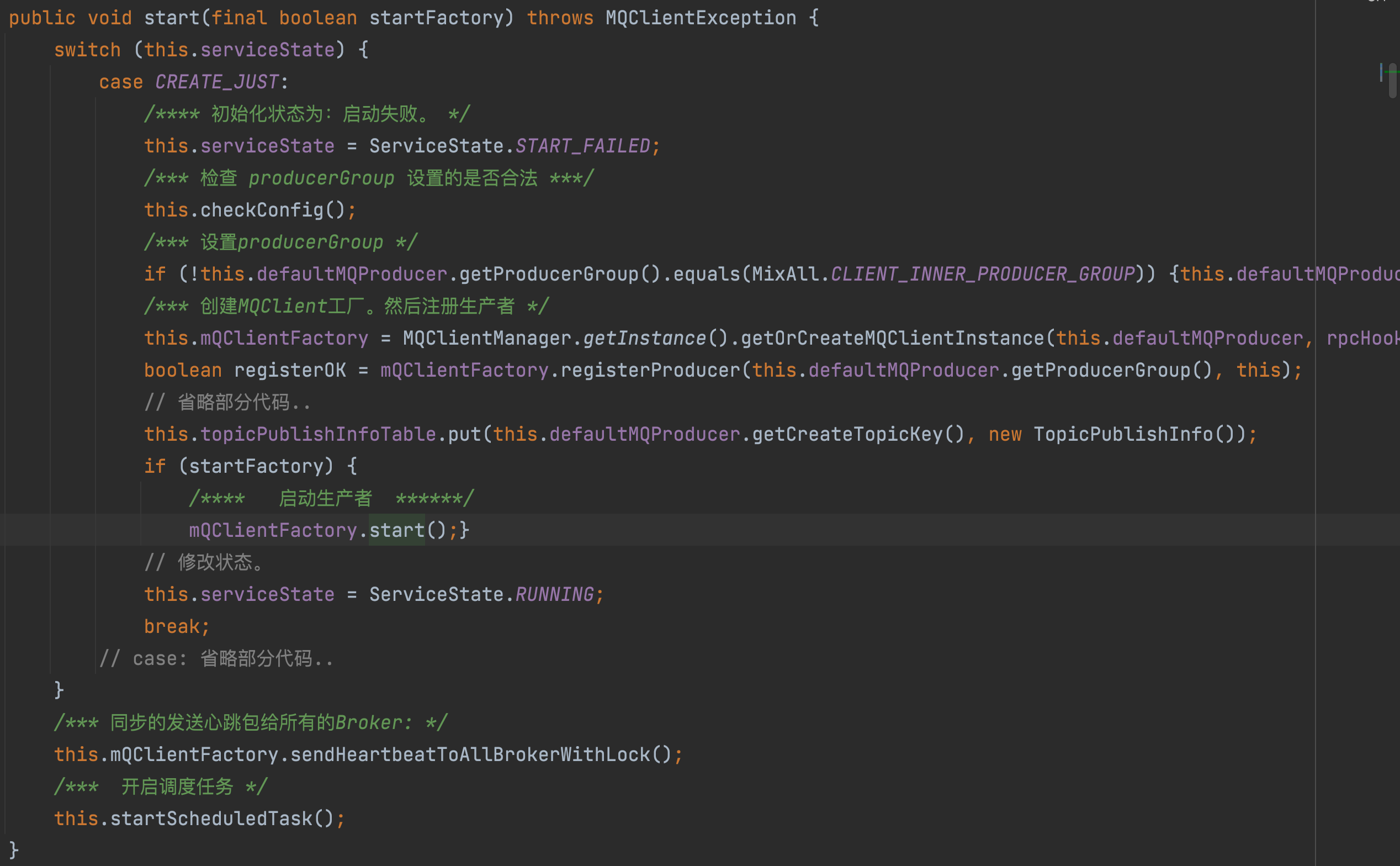
如上图
- 生产者首先会检查
producerGroup的合法性。 - 然后设置
ProducerGroup - 创建
MQClientFactory. 将producer注册到MQClientInstance中, - 初始化
topicPushlishInfo.topicPushlishInfo主要用于存放消息的路由信息。 - 然后通过
mQClientFactory.start()完成启动,这一步骤很重要,我们来看一下里面的具体实现.
![]()
- 1. 首先会设置
NameServerAddr。前面有说过可以通过DefaultProducer的setNameSrvAddr方法手动设置,也可以通过系统变量的方式进行设置NameServer的地址:System.setProperty("rocketmq.namesrv.domain", "localhost"); - 2. 开启定时任务:总共启动了
5个定时器任务,分别是:定时更新NameServerAddr信息,定时更新topic的路由信息,定时清理下线的broker,定时持久化Consumer的Offset信息,定时调整线程池; - 3.
pullMessageService和rebalanceService被用在消费端的两个服务类,分别是:从broker拉取消息的服务和均衡消息队列服务,负责分配消费者可消费的消息队列
- 1. 首先会设置
- 同步的发送心跳给所有的
Broker. - 开启定时任务:定时扫描过期的请求。
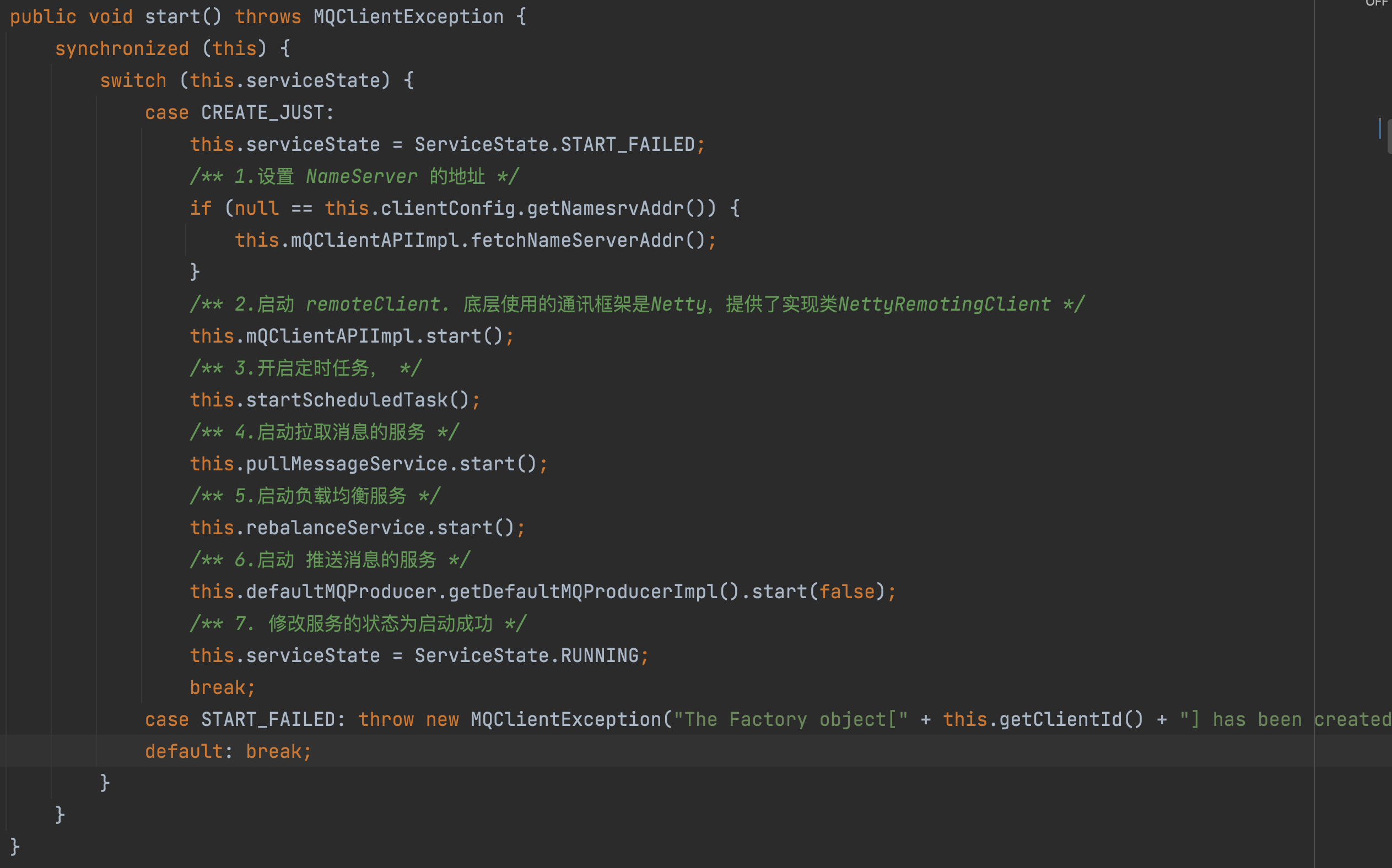
# 生产者发送消息
生产者启动完成之后,我们再看一下发送消息的过程:
发送消息的逻辑主要是在 sendDefaultImpl 方法中。主要逻辑分成三步:1. 获取队列的路由信息,2. 获取 MessageQueue , 3. 发送消息。
# 获取队列路由信息
在 启动生产者流程中,已经将 topic 的路由信息存储到了 topicPushlishInfo 中,并以 producerGroup 为 key , topicPushlishInfo 为 Value ,存储到 topicPublishInfoTable 这个 Map 中。
获取路由信息则是通过 mQClientFactory.updateTopicRouteInfoFromNameServer(topic, true, this.defaultMQProducer) 获取的。此方法根据 topic 获取路由信息,具体连接哪台 nameServer ,会从列表中顺序的选择 nameServer ,实现负载均衡;
# 获取 MessageQueue
获取 MessageQueue 则是通过 this.mqFaultStrategy.selectOneMessageQueue(tpInfo, lastBrokerName) 来实现的。 MQFaultStrategy 这个类实现了选择 MessageQueue 的策略。主要有四种策略:
latencyFaultTolerance:延迟容错对象,维护brokers的延迟信息;sendLatencyFaultEnable:延迟容错开关,默认不开启;latencyMax:延迟级别数组;notAvailableDuration:根据延迟级别,对应broker不可用的时长;
获取 MessageQueue 之后需要判定其对应的 Broker 是否可用,同时也需要和当前指定的 brokerName 进行匹配;如果没有获取到就选择一个延迟相对小的, pickOneAtLeast 会做排序处理;如果都不行就直接获取一个 MessageQueue ,不管其他条件了
# 发送消息
首先需要获取指定 broker 的地址,这要才能创建 channel 与 broker 连接;然后就是一些 hook 处理;接下来就是准备发送的消息头 SendMessageRequestHeader ,最后根据不同的发送策略执行发送消息。
之前的文章中说过, RocketMQ 发送消息有三种方式:同步,异步和单向。具体的使用方法可以参考这篇文章。在 RocketMQ 的生产者端可以发送多种类型的消息包括:延迟消息,顺序消息以及事务消息, 各种消息的发送过程我会在后面通过源码仔细和大家一起学习~。
# 生产者关闭流程
生产者的关闭主要有四步
- 取消生产者的注册.
- 关闭
MqClient=> 主要是关闭生产者,关闭拉取消息服务,关闭定时任务服务,关闭远程 client,关闭负载均衡服务这 5 种服务。 - 关闭
Producer的定时任务 - 修改状态。
这样就完成了生产者的关闭流程。
# 生产者总结
生产者首先需要设置 namesrv ,或者指定其他方式更新 namesrv ;然后从 namesrv 获取 topic 的路由信息,路由信息包括 broker 以及 Message Queue 等信息,同时将路由信息保存在本地内存中,方便下次使用;最后从 Message Queue 列表中选择合适的 Queue 发送消息,实现负载均衡;
# Consumer
现在我们还剩下 消费者 的启动流程了。从一个简单的例子说起:
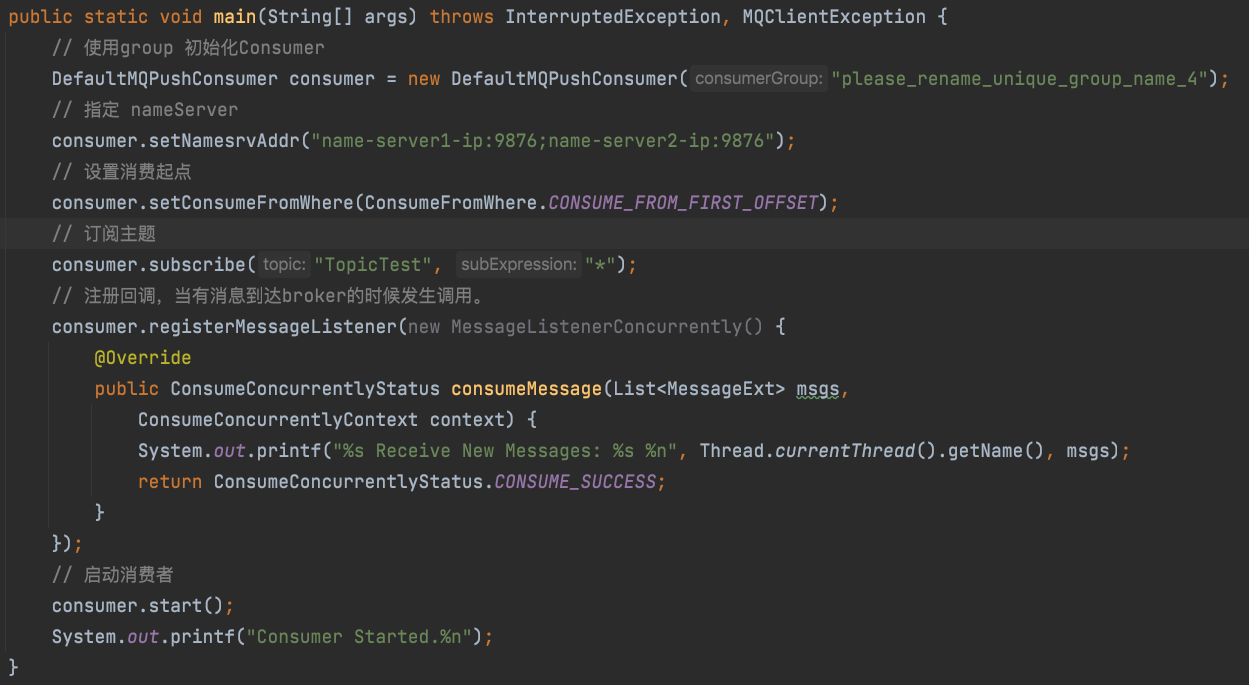
从图中可以看到使用 MQ 的消费者主要分成三部分: 1. 创建消费者对象,2. 配置消费的属性 nameServer, 消费起点,订阅主题,回调事件等。3. 启动消费者。
# Consumer 的启动过程
正如上文所说, 启动 MQ 消费者主要分为三部分,我们主要讲述第一部分和第三部分:创建 Consumer 对象,启动。
# 创建 Consumer 对象
RocketMQ 支持两种消息消费模式, pull 模式 和 push 模式。 pull 模式是消费者主动拉取消息, push 模式是 broker 端主动推送消息给消息者端。可想而知, push 模式是不管消费者端死活的,只要有消息就会推给消费者端,不管消费者是否能消费完。而 pull 模式是不管 Broker 端的,可能会造成消息积压的问题。
RocketMQ 分别提供了 pull 模式 和 push 模式的消费者的支持。类结构如下图:
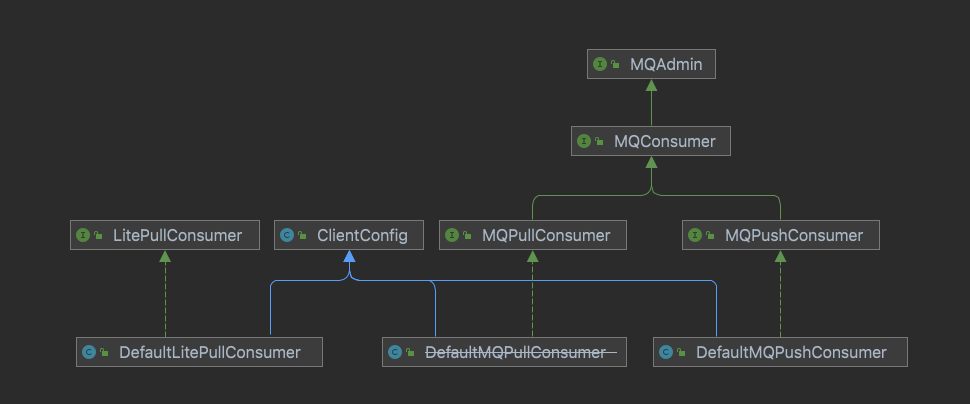
图中 push 模式,提供了 MQPushConsumer ( DefaultMQPushConsumer ) 类来实现。 pull 模式提供 MQPullConsumer ( DefaultMQPullConsumer ) 类来实现。但是这个已经标记为废弃,并在 2022 年会移除,提供了 LitePullConsumer ( DefaultLitePullConsumer ) 来实现 Pull 模式。
# 创建 DefaultMQPushConsumer 对象
DefaultMQPullConsumer 对象的构造参数
consumerGroup: 消费者组namespace: 生产者的NamespaceallocateMessageQueueStrategy: 消息队列分配算法rpcHook:rpc的钩子,用在远程调用之前执行enableMsgTrace: 是否跟踪消息轨迹customizedTraceTopic: 跟踪消息轨迹使用topic
在 DefaultMQPushConsumer 的构造方法中会创建 DefaultMQPushConsumerImpl 对象,我们后面所说的启动过程,其实就是 DefaultMQPushConsumerImpl 的启动过程,即 DefaultMQPushConsumerImpl.start() .
# 创建 DefaultLitePullConsumer 对象
DefaultLitePullConsumer 对象的参数:
namespace: 生产者的命名空间consumerGroup: 消费者组rpcHook: RPC 的回调钩子
在 DefaultLitePullConsumer 的构造方法中会创建 defaultLitePullConsumerImpl 对象。而后面的启动过程,即是 DefaultLitePullConsumerImpl 的启动过程。即 DefaultLitePullConsumerImpl.start() .
# 启动
这里我再把使用 DefaultMQPushConsumer 消费消息的案例 粘贴到这里
我们主要看 consumer.start() 内部的具体实现。
# push 模式: DefaultMQPushConsumerImpl.start ()
- 检查必要的参数
consumerGroup, 消费模式,消费起点,负载策略等。 - 拷贝订阅关系,绑定到重试
topic, 以防止消费者ack失败。 - 创建
MQClientInstance实例。这里是一种单例模式。 - 配置消费者再平衡的消费者组,消息模式,消息的分配策略,
MQClientInstance实例。 - 实例化消息拉取的包装类 并注册消息过滤的钩子
- 加载消息的消费偏移量。 如果是广播消息从本地获取偏移数据,如果是集群消息的话,则从远程获取偏移数据
- 启动消息消费服务。这里只是启动消费服务,但是没有启动开始消费消息。
- 绑定消费者
group和 消费者 - 启动
MQ Client Instance. 这里,在生产者中也调用了mQClientFactory.start(); 方法。有个疑问,为什么消费者会启动消息推送服务呢?因为在push模式下,消费超时的消息会重新发送给Broker。所以是会使用消息推送服务的. - 从
NameServer拉取topic的订阅信息 - 向
Broker校验客户端 - 向所有的
Broker的master节点发送心跳包,并上传FilterClass源文件给FilterServer - 立即消费消息: 将当前
consumer负载得到的MessageQueue全部添加到PullMessageService.pullRequestQueue(阻塞队列) 然后PullMessageService服务会开始拉取消息。消费消息。
# pull 模式: DefaultLitePullConsumerImpl.start()
先看下 DefaultLitePullConsumer 的一个简单使用:
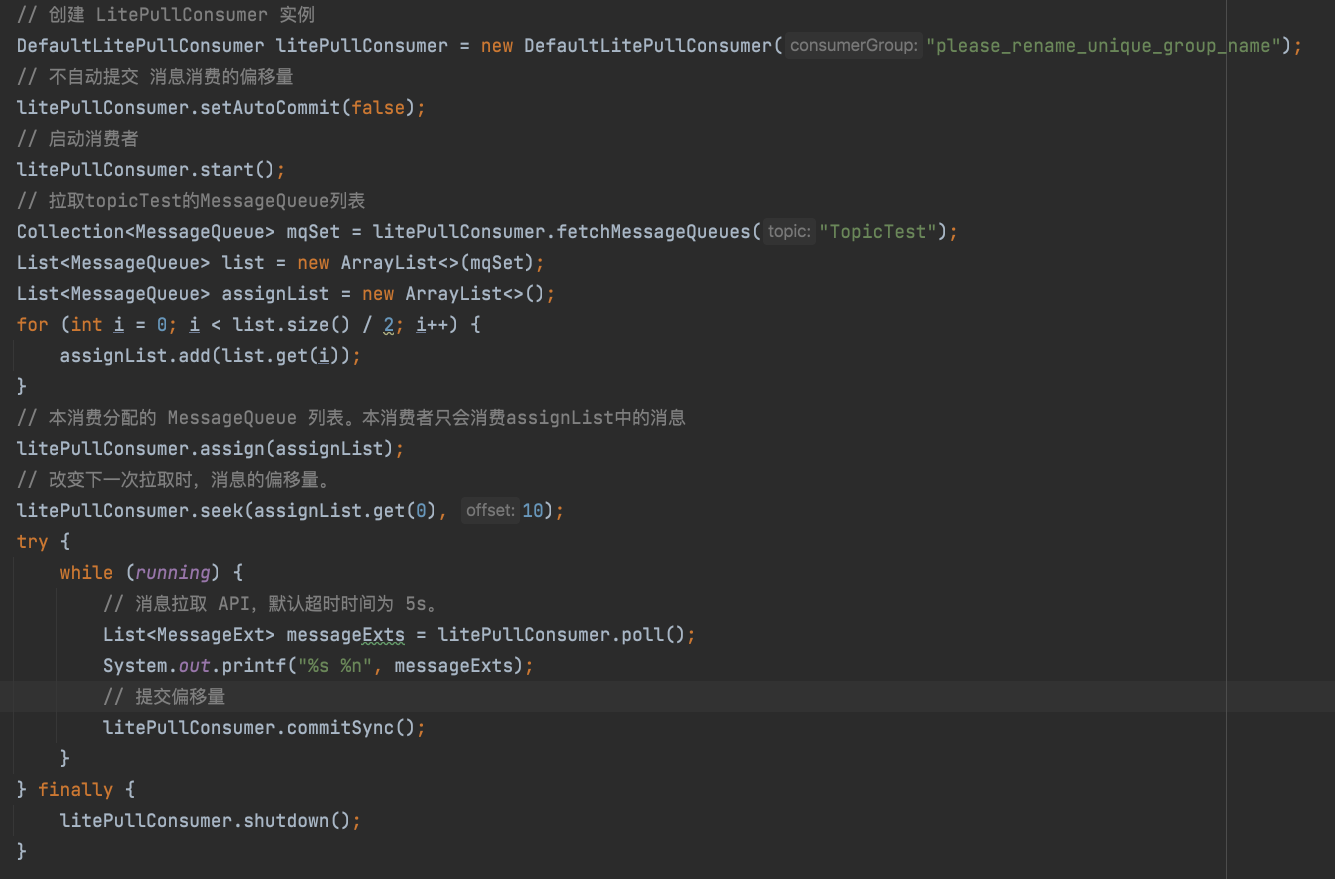
DefaultLitePullConsumer 的实现代码要比 DefaultMQPushConsumer 的代码 规整很多。在 start() 方法中定义了很多的子方法进行调用。
- 检查属性配置是否合法。
- 初始化
MqClientInstance.- 创建
MQClientInstance实例 - 注册
consumerGroup和 当前消费者的关系
- 创建
- 初始化 消息消费的 再平衡 服务。
- 配置消费者再平衡的消费者组,消息模式,消息的分配策略,
MQClientInstance实例。 - 实例化消息拉取的包装类 并注册消息过滤的钩子
- 加载消息的消费偏移量。 如果是广播消息从本地获取偏移数据,如果是集群消息的话,则从远程获取偏移数据
- 启动
MqClientInstance实例- 设置
NameServer的地址 - 启动
remoteClient. 底层使用的通讯框架是Netty,提供了实现类NettyRemotingClient - 开启定时任务
- 启动拉取消息的服务
- 启动负载均衡服务
- 启动推送消息的服务
- 修改服务的状态为启动成功
- 设置
- 启动后操作
- 如果是广播的模式:更新
topic的订阅关系 - 更新消息拉取任务
- 拉取
Topic的messageQueue. - 检查
Broker Client
- 如果是广播的模式:更新
# Pull 模式 和 push 模式的对比
现在去谈 push 和 pull 两种模式的对比,还为时尚早,我就先从启动上来看下,两种方式启动的不同点:
pull模式没有拷贝订阅关系,也就是说pull模式下,RocketMQ是没有提供重投机制的。pull模式没有和Broker保持心跳包。 如果消费者过多的时候,push 模式必然会对 Broker 造成比较啊的压力。
# 消费者总结
RocketMQ 对 pull 和 push 两种消息的消费模式提供了支持。 pull 模式,对应的实现是 DefaultMqLitePullConsumer 。 push 模式对应的实现是 DefaultMqPushConsumer . 仅仅对启动过程,两者的启动过程稍有不同。 Push 模式下, RocketMQ 封装了 消息消费的重投机制, pull 模式则没有,一切都需要消费者自己去实现。 push 模式会把 根据 MessageQueue 的分配策略,将 MessageQueue 拉取到本地,存储到阻塞队列中,然后通过回调消费者注册监听器进行消费。 pull 模式则通过在消费逻辑中定时的轮询获取消息进行消费。 下一篇文章,我会仔细的分析消息消费的过程。
不管是 Pull 模式,还是 push 模式,在启动过程都是 创建 MqClientInstance 实例,并启动。
# 最后
期望和你一起遇见更好的自己

