学东西的时候最好是理论先行,为什么?没有理论,想当然的去干,干好了是 瞎猫碰上死耗子,干不好就瞎干,浪费时间,只会弄得身心俱疲。
可是在真正的工作中,很少工作会允许你先弄清原理再去实操。但是不管怎么说,欠下的债终究是需要还的。
今天咱们的主题是 stream . 咱们就从 Stream 的 "道,术,法,器" 四个阶段来聊好好的聊聊这个 Stream .
# 以 "器" 始:从使用开始
你平时是怎么使用
Stream的?
比如我会使用 Stream 创建一个流。
1 | Stream<Integer> integerStream = Stream.of(1, 2, 3); |
或者把一种集合类型转成 stream ,然后做一些聚合操作
1 | List<Integer> collect = list.stream() |
那在 jdk1.7 及以前的时候,我们是怎么处理的呢?
1 | // 遍历list,所有元素+5 |
根据上面的对比,我们很明显的就能对比出来:
stream 的编码方式,使代码更加简洁,可读性也比较强。而且 Stream 提供了集合的常用操作,比如 sort , 过滤 , 去重 , 计数 , limit , skip 等等,直接可以用,可以大大的提高开发效率。
那 Stream 为我们提供了多少功能呢?
从全局来看,所有和 stream 相关的类,都在 java.lang.stream 这包下。
这个包下有很多的类。总体来说,
流处理相关的操作分为两类:
- 中间操作 (
Intermediate Operations)- 无状态的中间操作 (
Stateless): 使用StatelessOp表示。每个操作都是互不影响,不依赖的。这类的操作有:filter()、flatMap()、flatMapToDouble()、flatMapToInt()、flatMapToLong()、map()、mapToDouble()、mapToInt()、mapToLong()、peek()、unordered()等 - 有状态操作(
Stateful):使用StatefulOp表示。处理时会记录状态,比如处理了几个。后面元素的处理会依赖前面记录的状态,或者拿到所有元素才能继续下去。如distinct()、sorted()、sorted(comparator)、limit()、skip()等
- 无状态的中间操作 (
- 终止操作 (
Terminal Operations):使用TerminalOp表示。- 非短路操作:处理完所有数据才能得到结果。如
collect()、count()、forEach()、forEachOrdered()、max()、min()、reduce()、toArray()等。 - 短路(
short-circuiting)操作:拿到符合预期的结果就会停下来,不一定会处理完所有数据。如anyMatch()、allMatch()、noneMatch()、findFirst()、findAny()等。
- 非短路操作:处理完所有数据才能得到结果。如
在深入探讨 stream 之前,我们需要储备些知识点。
-
函数式接口
FunctionInterfaceJDK提供了很多的函数式接口,包路径是:java.util.function. 函数式接口的作用是 Java8 对一类特定类型接口的称呼。这类接口只有一个抽象方法,并且使用@FunctionInterface注解进行注明。在Java Lambda的实现中, 开发组不想再为Lambda表达式单独定义一种特殊的Structural函数类型,称之为箭头类型(arrow type), 依然想采用 Java 既有的类型系统 (class,interface,method等), 原因是增加一个结构化的函数类型会增加函数类型的复杂性,破坏既有的Java类型,并对成千上万的Java类库造成严重的影响。 权衡利弊, 因此最终还是利用SAM接口 (Single Abstract Method) 作为Lambda表达式的目标类型。函数式接口其实在
Jdk8之前就已存在了,比如java.lang.Runnable,java.util.concurrent.Callable,java.util.Comparator等等。只是没有使用@FunctionInterface注解而已。在JDK1.8之后加上了这个注解,并且在java.util.function包下新增很多个函数式接口。 其中,我们需要知道的只有六个:Predicate: 传入一个参数,返回一个bool结果, 方法为boolean test(T t)Consumer: 传入一个参数,无返回值,纯消费。 方法为void accept(T t)Function<T,R>: 传入一个参数,返回一个结果,方法为R apply(T t)Supplier: 无参数传入,返回一个结果,方法为T get()UnaryOperator: 一元操作符, 继承Function<T,T>, 传入参数的类型和返回类型相同。BinaryOperator: 二元操作符, 传入的两个参数的类型和返回类型相同, 继承BiFunction<T,T,T>
为什么要了解这个 函数式接口呢?
因为 在 Stream 的方法中,大部分的参数都是使用 函数式接口 接受参数的。所以,如果要探究其实现原理和设计原则的话,这个是必须要知道的。
注意:
lambda表达式,是一种语法的表现形式,使代码表现更加整洁lambda和stream是两个不相关的概念。
# 查 "术" 理: (查看源码,明晰基本的类结构)
先来看下 和 Stream 直接相关的类。
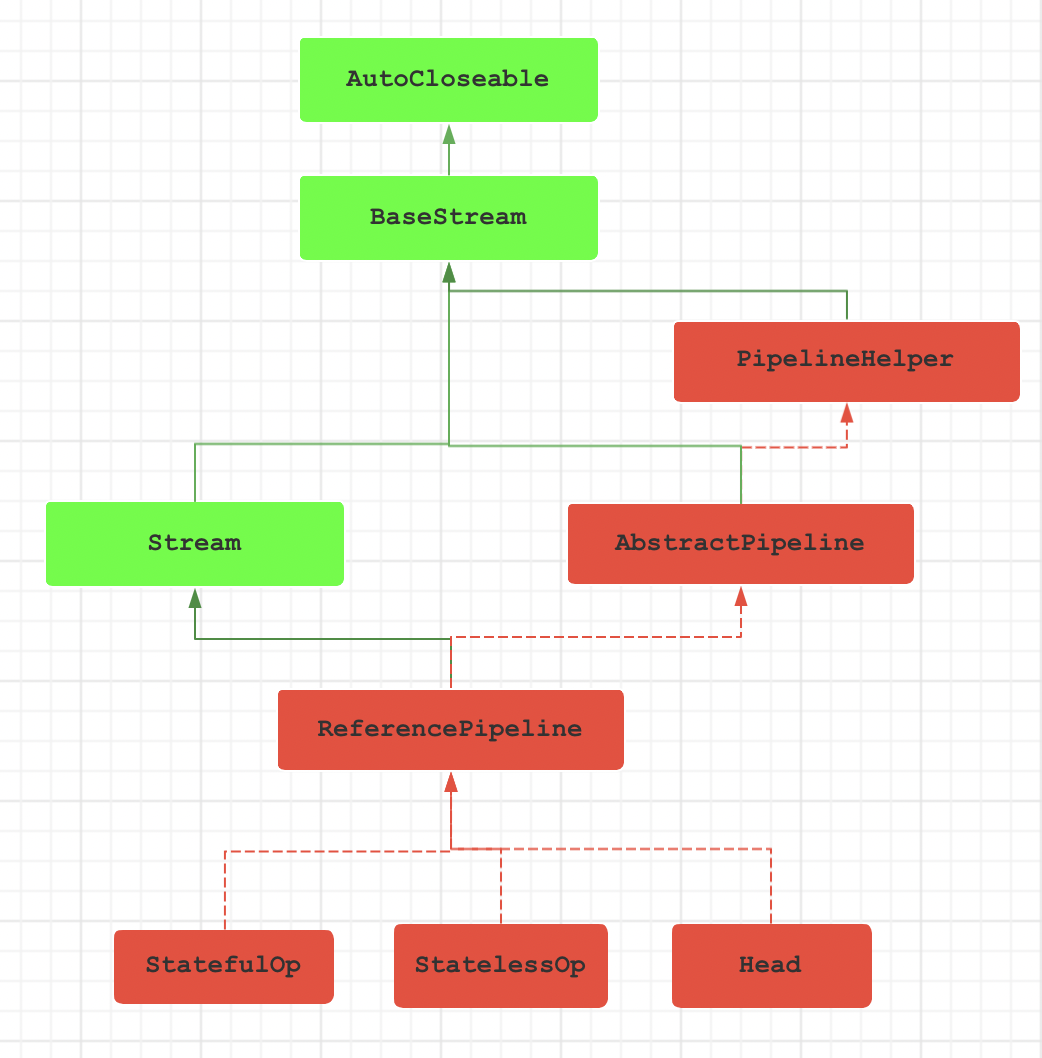
Stream 接口继承了 BaseStream 接口.
✔️ BaseStream 接口表示流的基本接口,而流是支持顺序和并行聚合操作的元素序列。
Stream 接口有很多实现类。其主要的一个实现类是 ReferencePipeline 类。除此之外 ReferencePipeline 类还继承了 AbstractPipeline 抽象类. ✔️ AbstractPipeline 表示 “管道” 类的抽象基类,它们是 Stream 接口及其原始特化的核心实现。再看 AbstractPipeline 类的父类 PipelineHelper ,✔️ AbstractPipeline 的作用是:用于执行流管道的辅助类,将有关流管道的所有信息(输出形状、中间操作、流标志、并行度等)集中在一个地方。
ReferencePipeline 类有三个子类: StatefulOp 表示有状态的操作, StatelessOp 表示无状态的操作, Head 表示 ReferencePipeline 的起始阶段。 当然了,这三个子类也是 流。
# 从创建流开始
不管是使用 Stream.of(T t) 还是 Collection.stream() ,还是 Arrays.stream() , 底层的实现都是通过 StreamSupport.stream() 来实现的。

✔️ StreamSupport 类的作用是:用于创建和操作流的底层实用方法。
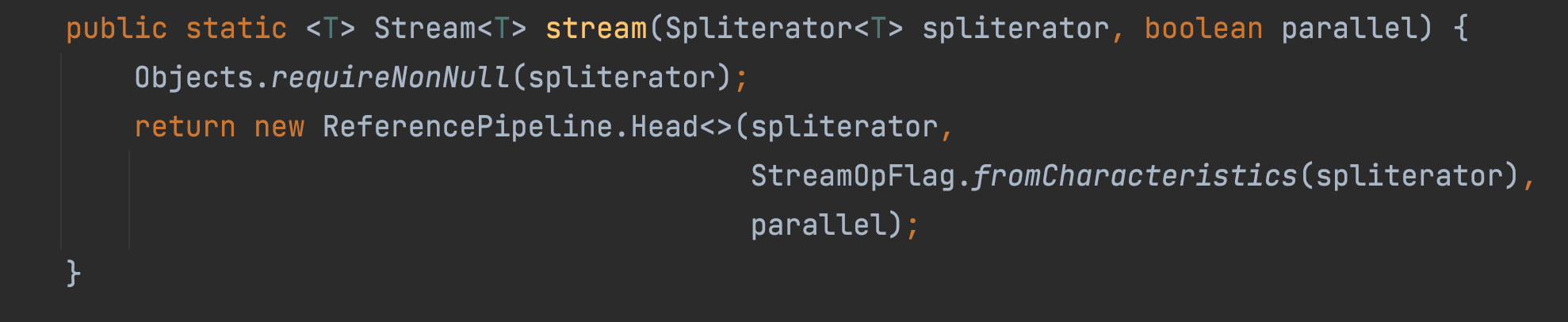
可以看到 直接返回的是 ReferencePipeline.Head 对象。 首先 Head 是一种 Stream 的实现。 接着去看 Head 的构造方法,可以看到其实调用的是: AbstractPipeline 的构造方法.
# 流的中间操作
文中已经谈及了 中间操作分为有状态的中间操作和无状态的中间操作。那我们以一个案例来说明操作与操作之间执行的。
1 | List<Integer> numbers = Stream.of(1, 2, 3, 4) |
Stream.of() 方法上文已经简单的说明了,接下来我们来看 map() 方法。
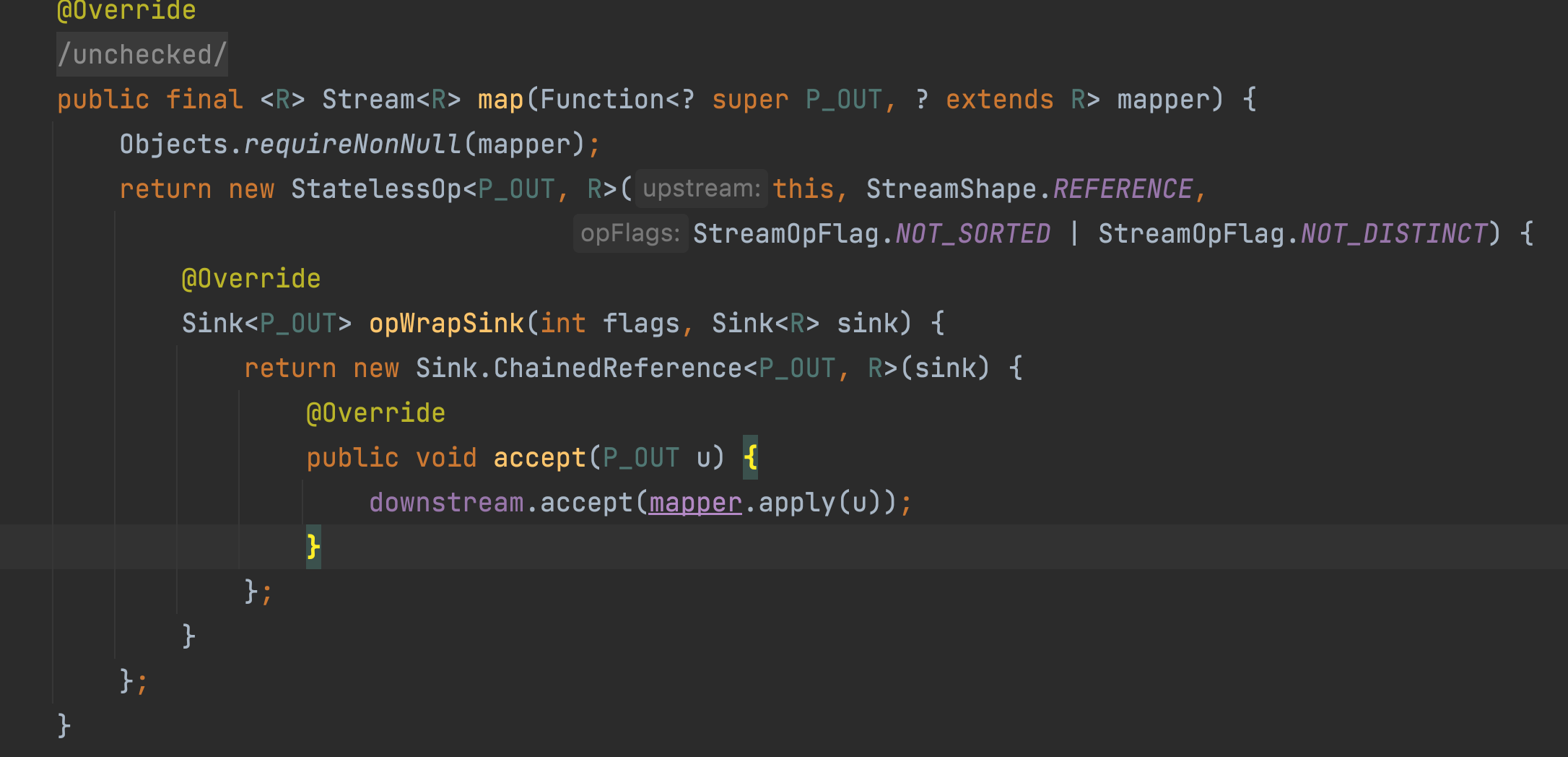
可以看到, map() 返回了一个 StatelessOp 对象,并且重写了 AbstractPipeline 的 opWrapSink 方法。 之前也说过:它表示流的无状态中间阶段的基类。 还有一个 Sink 类型. Sink 类表示 Consumer 接口的扩展,用于在流管道的各个阶段传递值,以及管理大小信息、控制流等的附加方法。
我们再仔细看一下这个方法。首先这个方法并没有进行任何的计算,只是将 item -> item + 5 这个操作进行三层的封装, 1. 将 map 方法的返回值重新封装成了流对象,2. 把我们的 item -> item + 5 这个操作封装成了 StatelessOp , 并重写了 opWrapSink 这个方法,并在终止操作时进行调用。 3. 使用 sink ( Sink.ChainedReference) 将管道的各个阶段连接起来。即赋值 downStream . 使用 downstream 这个 Consumer 完成 accept 调用。
这里需要注意一下: StatelessOp 类的构造方法的实体参传输了一个 this 字段。仔细翻看源码就会返现它一直调用到 AbstractPipeline 的构造方法中。
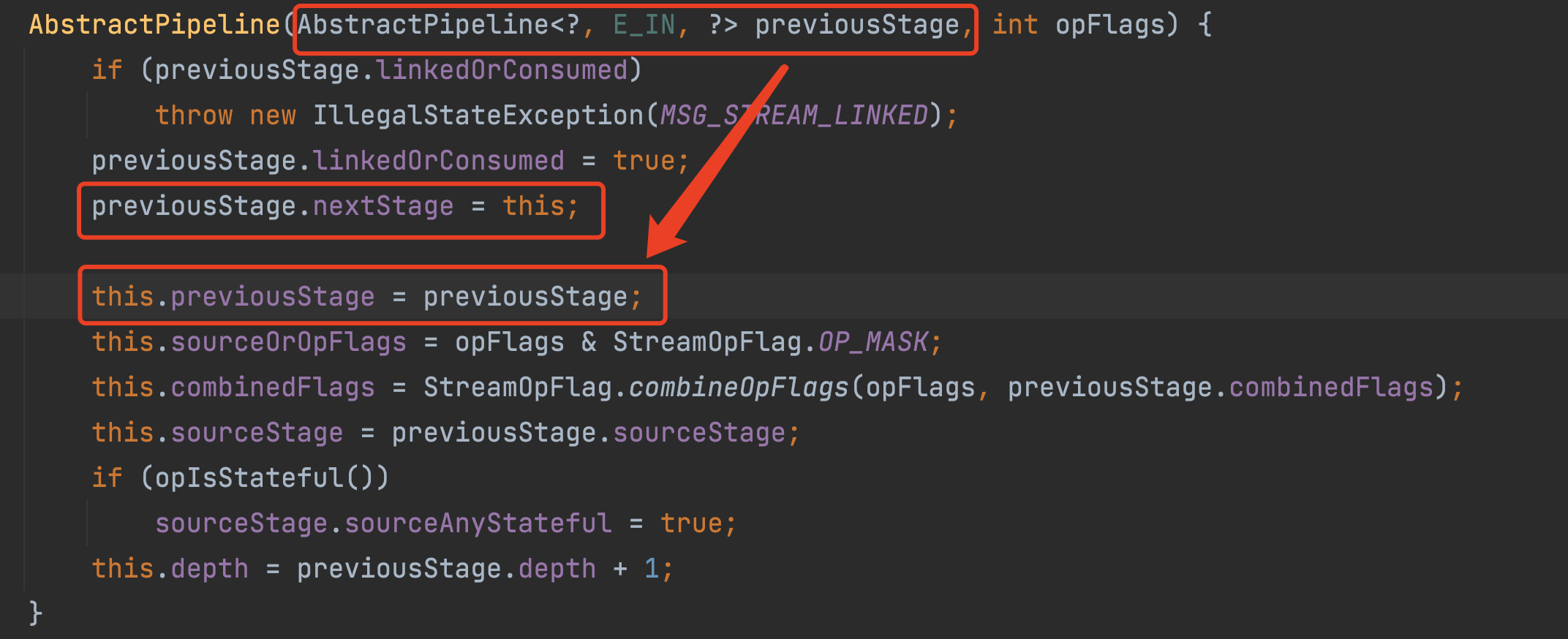
可以看到 AbstractPipeline 中有两个字段 nextStage 和 previousStage 字段,分别表示的是上一阶段和下一阶段。其中 nextStage 是 当前阶段。 previousStage 则应该 当前阶段的上一个阶段,其实就是调用当前方法的对象。
不知道你是否发现 通过这种方法, stream 组成了一个 流各个阶段的双向链表。节点就是流操作的各个阶段。
ps: 这样一次流操作会创建两个链表: Stream 阶段的双向链表,和 在终止操作时,根据双向链表生成的 Sink 链表。
再次说明:到目前为止, map() 方法里只是进行了封装,没有进行任何计算!
接着来看 sorted() 方法。
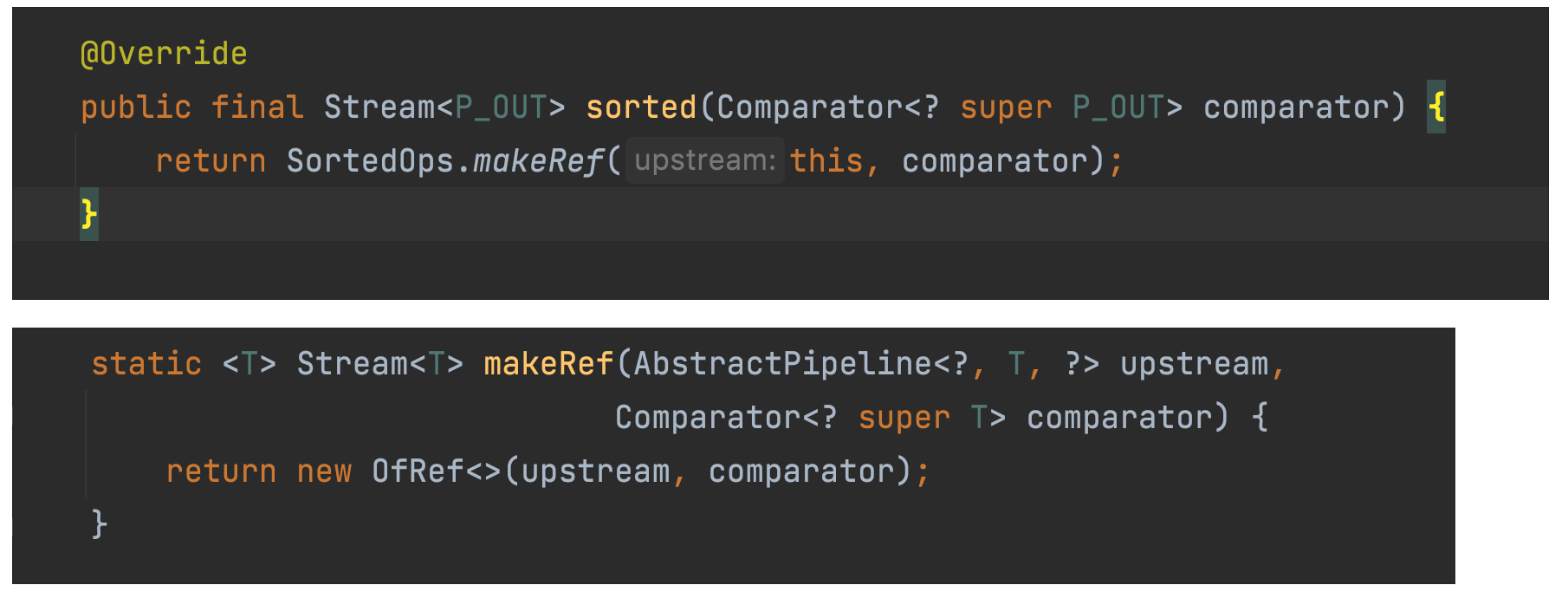
sorted 方法比较简单,通过调用 SortedOps 类的 makeRef 方法,创建了 OfRef 对象。 OfRef 类的作用是:用于对流进行排序的专用子类型。 OfRef 类继承了 ReferencePipeline.StatefulOp ,所以 OfRef 是一个有状态操作。那自然它也会有 opWrapSink 方法。也就是说它也会返回一个 Sink 对象,只是这个 Sink 对象的实现类不一样的。
说明:到目前为止,
sorted()方法里只是进行了封装,没有进行任何计算!
同理去看 limit 方法。
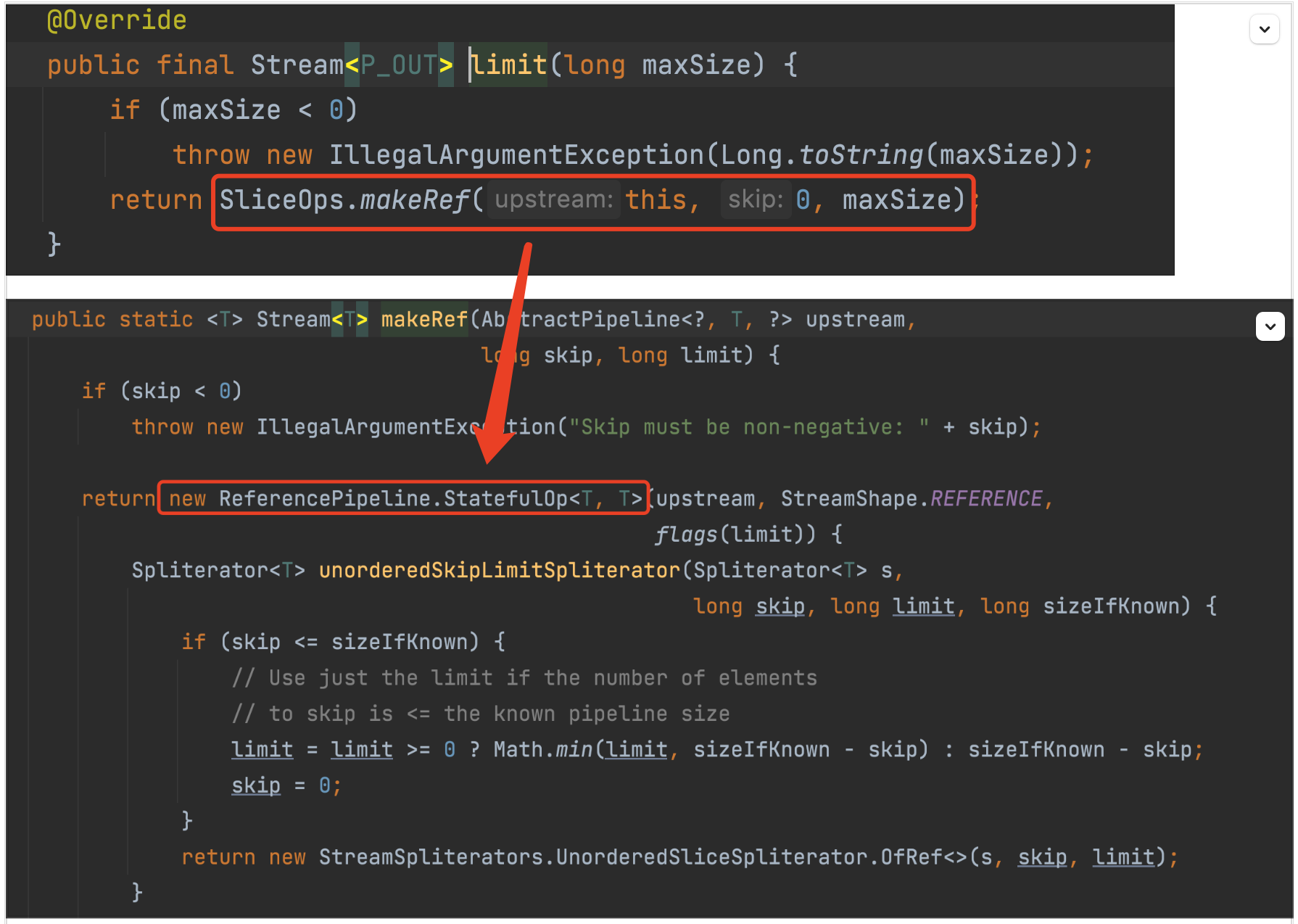
这个方法的内部是直接创建了一个 ReferencePipeline.StatefulOp 对象,也是重写了其中的方法: opWrapSink .
不知道你是否有好奇,我为什么每次都会提到 opWrapSink 这个方法呢?因为这个方法非常的重要!其重要性我们在 探” 法 “择 这部分会完整的说明。
再三说明:到目前为止,
limit()方法里只是进行了封装,没有进行任何计算!
书行至此,案例中的中间操作都已经简单的分析完成了。我们就知道这里 jdk 为了完成 流操作为每个中间操作都封装了很多的对象,而这些对象只是散列在了内存中。接下来,就要看 jdk 是如何把他们组装到一起的。
# 终止操作
以 Collect 方法为例,去探究一下终止操作的流程。
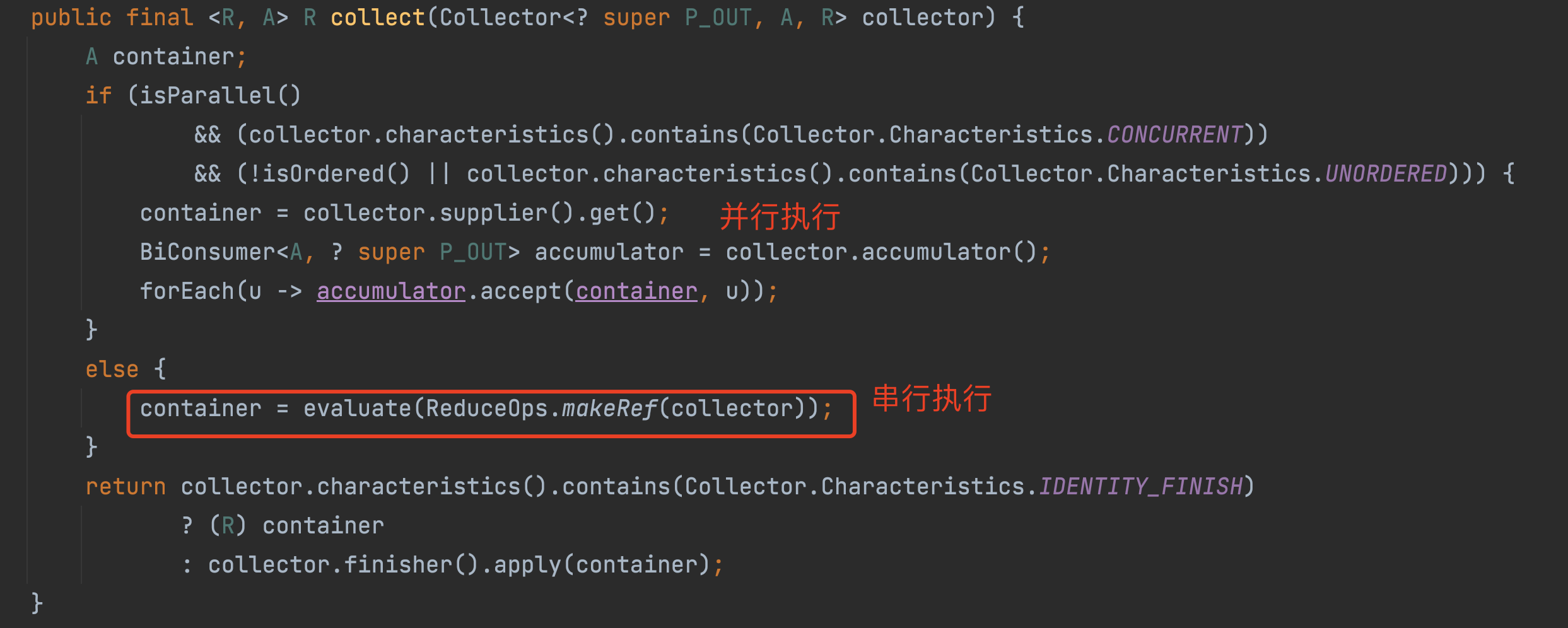
可以看到在 collect 方法中,分为并行执行方式和串行执行方法,我们看串行执行时,会创建 ReduceOps 终止操作对象。
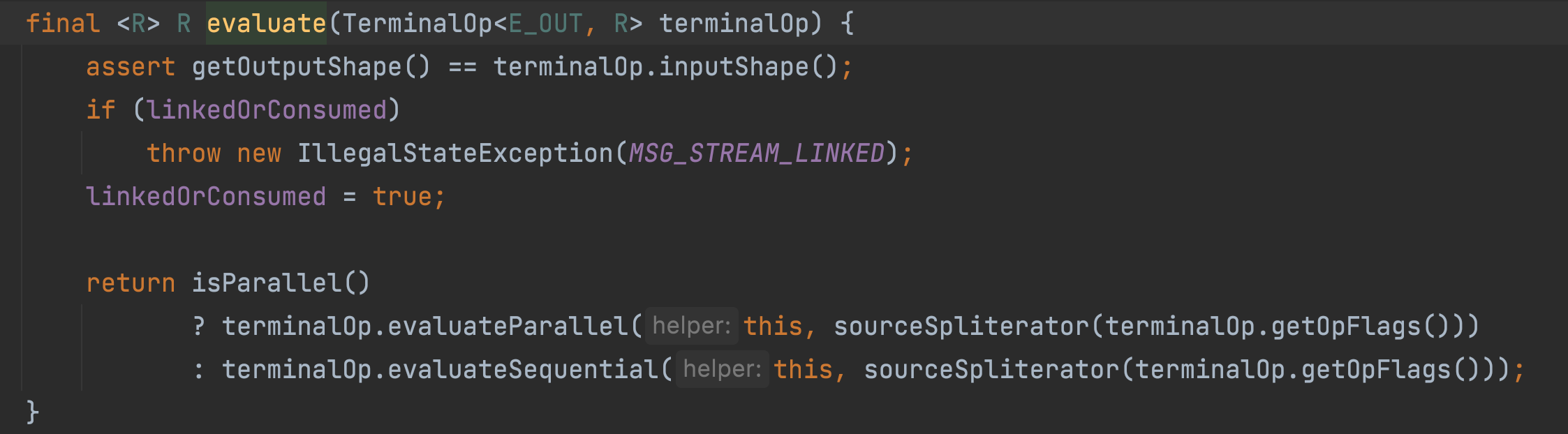
将 终止操作 传递给 evaluate 方法,然后调用终止操作的 evaluate 方法,当然这个方法也分成了串行执行和并行执行两种。
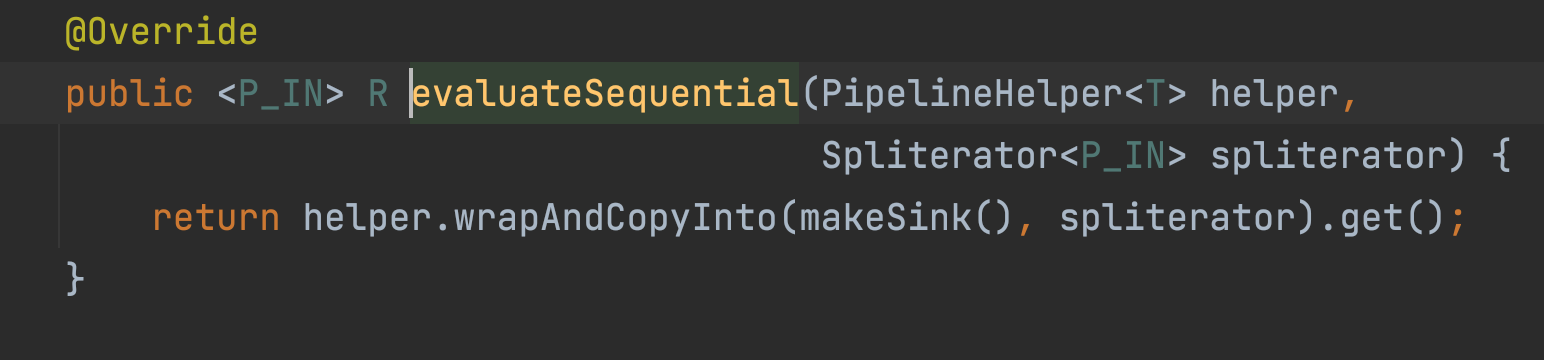
helper 其实是 limit(3) 中间操作返回的对象。这其实中间操作的最后一个 Stage (阶段)。返回的对象是 AbstractPipeline 和 Stream 的子类实例。

这里包含两个方法: wrapSink() 和 copyInfo() .
这是两个非常重要的方法. wrapSink() 是将中间的操作组成 SinkChain 。 copyInfo() 这是执行真正的计算逻辑。
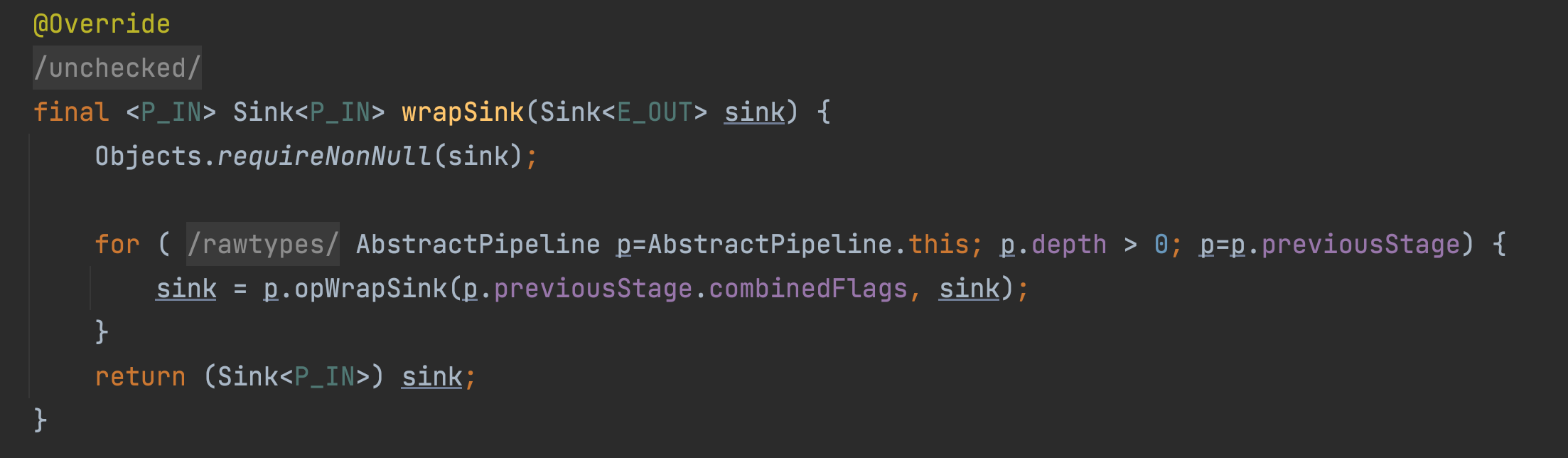
方法中的形参 sink 就是最后的阶段的终止操作。方法通过循环将 sink 分装到 Sink 中。 Sink 接口 的一个实现类是 ChainedReference , 类中定义了一个 downStream 字段。 会将 sink = p.opWrapSink(p.previousStage.combinedFlags, sink); 中的 sink 赋值给 downStream . 这样就形成了 套娃。 最后返回一个 wrapSink , 即整个流操作中所有的操作的 封装 Sink .
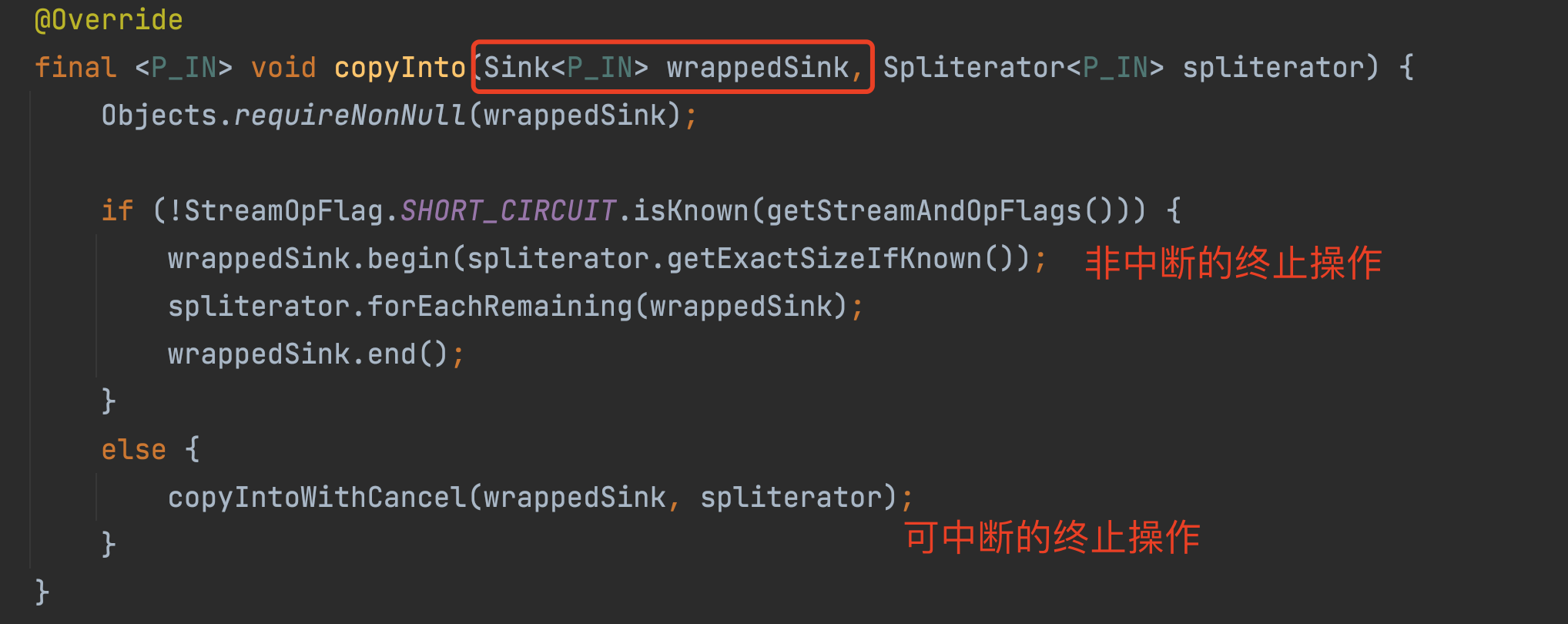
图中所示的即为上面提及的 封装 Sink . 可中断和不可中断的区别是:可中断如果获取值,就不必再取所有的结果了。反之,就需要计算出所有阶段的结果。
非可中断的终止操作时,会执行 begin() , forEachRemaining() , end() , 三个方法。 这个三个方法对应的是: Sink 接口中提供的三个方法。
1 | // 每个Sink开始之前调用该方法,通知sink做好准备 |
其中,
begin()方法,会调用每个Sink子类的begin方法。forEachRemaining()方法对应的执行内容如下图:
![]()
end()方法,会调用每个Sink字段的end方法。
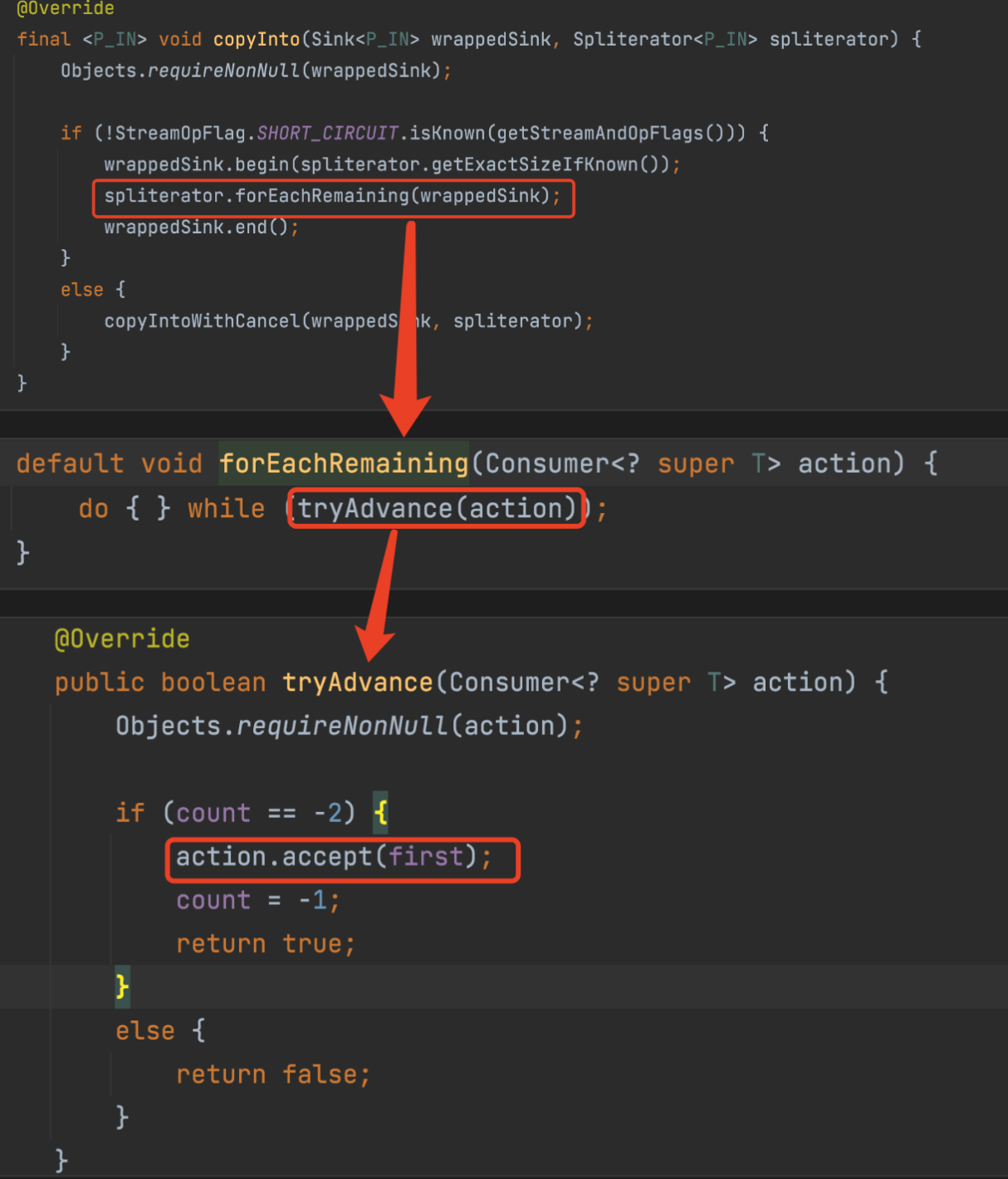
书行至此。或许你会对 forEachRemaining 方法感到好奇。后面我会写一篇文章来专门分享: 《 Stream 的高级迭代器》, 希望你能继续关注支持我~
# 探” 法 “择
我们从一个案例出发,在细节之处分析了一个 Stream 的执行过程。现在我们需要从全局来看一下 Stream 的执行过程是什么样子的.
上文中我们知道了 Stream 的 所有计算都是在 终止操作时 触发的。 所有的中间操作都是封装了一些对象。我们用一张图来描述下 Stream 的执行过程。
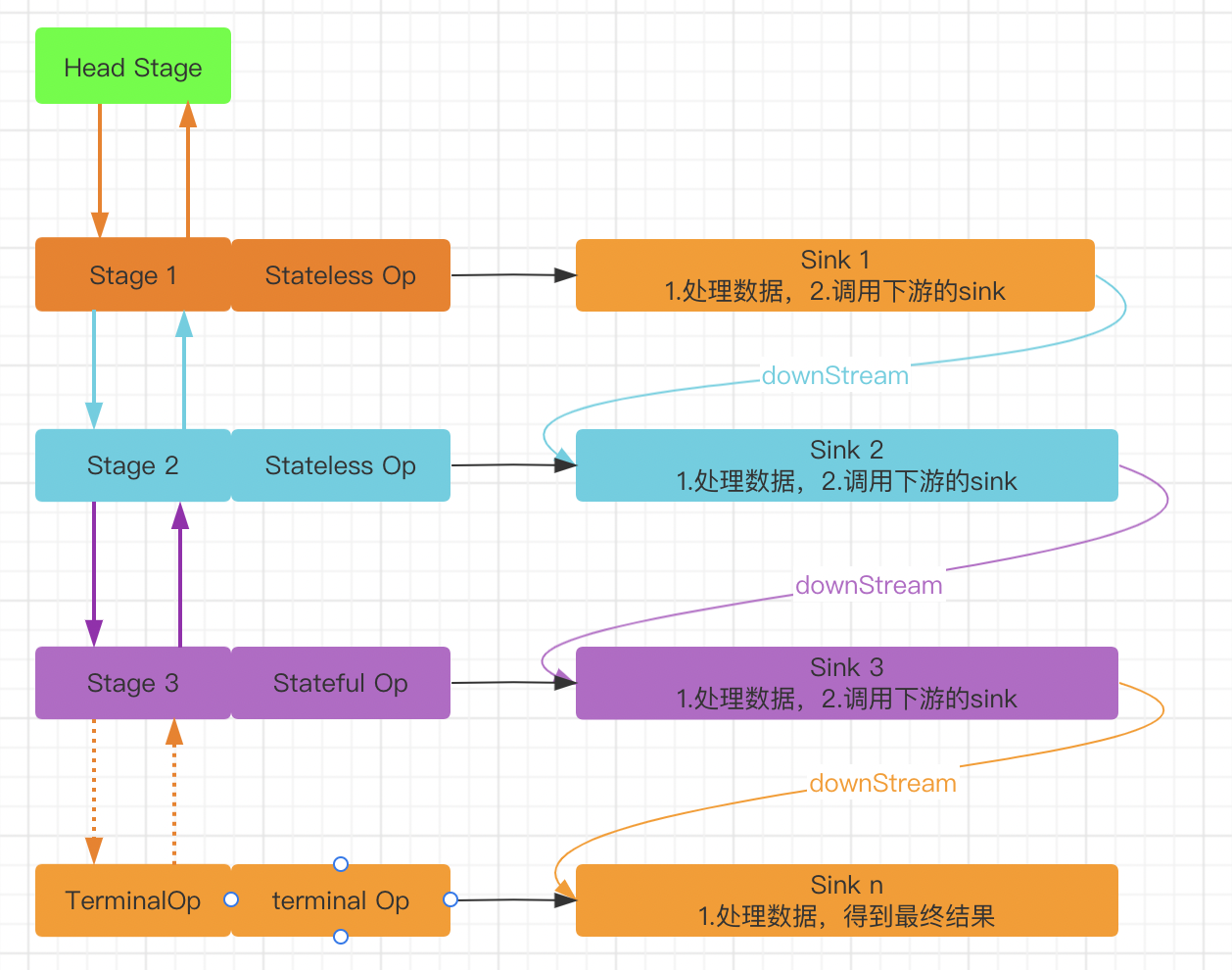
stream将创建的流做为第一个Stage, 用来代表流的开始, 每个Stage都是AbstractPipeline的子类。 第一个Stage是AbstractPipeline.Head对象。- 然后将中间操作封装成后面的 n 个
stage. 并组成 双向链表的形式,并且存储了stage0. 每个Stage都是StatelessOp或者statefulOp. - 终止操作通过
wrapSink()方法 会触发将 每个阶段的操作封装成Sink. 并且sink都会做为参数传递到上一个阶段的opWrapSink()方法中,从而组成一个sink链表。 - 然后,通过
copyInfo()方法将,交于Spilterator进行迭代。计算的结果可以分为四种- 返回
boolean类型的结果:比如anyMatch()allMatch()noneMatch()方法。 - 返回
Optional类型的结果: 比如findFirst()findAny()方法 - 还有归约操作:
reduce()collect() - 返回数组的:
toArray()
对于表中返回boolean或者Optional的操作(Optional是存放 一个 值的容器)的操作,由于值返回一个值,只需要在对应的Sink中记录这个值,等到执行结束时返回就可以了。
对于归约操作,最终结果放在用户调用时指定的容器中(容器类型通过收集器指定)。collect(),reduce(),max(),min()都是归约操作,虽然max()和min()也是返回一个Optional,但事实上底层是通过调用reduce()方法实现的。
对于返回是数组的情况,毫无疑问的结果会放在数组当中。这么说当然是对的,但在最终返回数组之前,结果其实是存储在一种叫做Node的数据结构中的。Node是一种多叉树结构,元素存储在树的叶子当中,并且一个叶子节点可以存放多个元素。这样做是为了并行执行方便。关于Stream的并行计算,我后面会继续分享。
- 返回
# 明 "道" 义
JDK 提供的 Stream 具有如下特点:
- 无存储。
stream不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java容器或I/O channel等。 - 为函数式编程而生。对
stream的任何修改都不会修改背后的数据源,比如对stream执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新stream。 - 惰式执行。
stream上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行。 - 可消费性。
stream只能被 “消费” 一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成。
在这一趴,我就围绕两个点来简单的聊聊。
JDK8为什么要加入Stream.
除了上面四个特点之外, Java8 中的 Stream 是对集合对象的增强,当然不仅仅是集合对象。 Stream 为开发者提供了简洁的编码方式和编码风格,极大的提高了开发的效率。
另外一个更重要的点在于 Stream 为我们下篇文章要分享的 Stream 并行计算流 提供了实现,请期待。
Stream为什么要这么设计?
我这里给一份我的回答,这个问题也留给看文章的你,也希望能看到你的回答。
根据上文所说的内容, Stream 体系是一组接口家族, AbstractPipeline 是接口的实现, PipelineHelper 是管道的辅助类, StreamSupport 是流的底层工具类
Stream 使用 stage 来抽象流水线上的每个操作,其实每个 stage 就是一个 stream 子类的实例, 也就是 AbstractPipeline 几个子类的内部子类即 Head StatelessOp statefulOp ;
StreamSupport 用于创建生成 Stream 对应的是 Head 类,其他的中间操作分为有状态和无状态的,中间操作通过方法比如 filter map 等返回的是 StatelessOp 或者 statefulOp . 多个 stage 组合称为双向链表的形式 从而成了整个流水线
有了流水线,相邻两个操作阶段之间如何协调运算?
于是又有了 Sink 的概念,又来协调相邻的 stage 之间计算运行
他的模式是 begin accept end 还有短路标记
他的 accept 就是封装了回调方法,所以说每个操作 stage , StatelessOp 或者 statefulOp 中又封装了 Sink . 通过 AbstractPipeline 提供的 opWrapSink 方法可以获取这个 Sink
调用这个 sink 的 accept 方法就可以调用当前操作的方法
那么如何串联起来呢?
关键点在于 opWrapSink 方法,他接收一个 Sink 作为参数,在调用 accept 方法中。可以调用这个入参 Sink 的 accept 方法
这样子从当前就能调用下一个,也就是说有了推动的动作。那么只需要找到开始,每个处理了之后都推动下一个,就顺序完成了所欲的操作了。
# 结语
通过看 Stream 相关的知识点,发现一篇文章是没法讲清楚的。
这一次,我又果不其然的留下了两篇文章
请给我记代办~
在分享 并行计算流 的时候,我们需要以 JDK1.7 中的 forkJoin 框架为前提,来分析 Stream 的 parallelStream .
在分享 迭代器 的时候,我们也会分析一下 JDK 中提供的 普通迭代器,比如 ForEach , iterator , 以及 Stream 的高级迭代器 spliterator . 也会由浅入深的分析一下,各种迭代器的优缺点。 也会自定义实现一个迭代器。
敬请期待,防止走丢见文末。关注我,期望和你一起遇见更好的自己.
# 最后
期望和你一起遇见更好的自己

