# 解密 ziplist.
为什么叫解密 ziplist 呢?因为从 ziplist 中取到我们预期的值,真的和解密一样!烧脑,但是极其有趣!!
# 引题
在介绍 Redis 的数据类型 list 的时候,是我们第一次接触 ziplist 这一数据结构。
不知道是否还记得 ziplist 这种数据结构的特性。如果不记得也没有关系,今天我们来详细的看下这个数据结构。
# 重读 ziplist 数据结构
ziplist 是经过特殊编码的双向链接列表,旨在提高内存效率。 它同时存储字符串和整数值,其中整数被编码为实际整数,而不是一系列字符。它允许在 O(1) 时间在列表的任一侧进行推和弹出操作。
但是,由于每个操作都需要重新分配 ziplist 使用的内存,因此实际的复杂性与 ziplist 使用的内存量有关。
ziplist 的数据结构总览。如下图

我来依次解释下这 5 个部分.
-
<uint32_t zlbytes>: 存储的ziplist占用的字节数 (包含zlbytes字段本身的4个字节)。因此:无需遍历就能直接知道这个数据结构的大小。 -
<uint32_t zltail>是列表中最后一个条目的偏移量。 这允许在列表的另一端进行弹出操作,而无需完全遍历。在任意一端进行pop和push操作的时间复杂度都是O(1). -
<uint16_t zllen>是条目数。当条目数超过2 ^ 16-2时,此值将设置为2 ^ 16-1,这时,我们需要遍历整个列表以了解其包含多少项了。 -
<uint8_t zlend>是代表ziplist末尾的特殊条目。编码为等于255的单个字节。 -
<entry>: 往下看.
# Entry
ziplist 中的每个条目都以包含两个信息的元数据作为前缀。首先,存储前一个 entry 的长度,以便能够从后到前遍历列表。第二,提供 entry 编码。 它表示条目类型,整数或字符串,对于字符串,还表示字符串有效负载的长度。因此,能够像下面这样存储一个完整的 entry .

有时, encoding 也可以代表 entry 本身,就像后面将要看到的小整数一样。在这种情况下, <entry-data> 部分丢失了,我们的 Entry 结构是这样的:
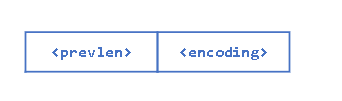
我们来具体看下 Entry 的编码方式.
# prevlen
<prevlen> 表示 前一个 entry 的长度。
-
如果 前一个
entry的长度小于 254 个字节,那么这个Entry只会消耗一个字节来表示该长度。一个无符号的8位整数。 -
如果前一个
entry长度大于或等于254字节的时候,它将占用 5 个字节。第一个字节设置为254(FE), 以指示随后的值更大。 其他的四个字节将作为前一个 entry 的长度的值。
所以,我们就能知道了 下面这种编码方式.
<prevlen form 9 to 253> <encoding> <entry-data>
或者
<prevlen 4 bytes unsigned little endian prevlen> <encoding> <entry-data>
# encoding
entry 中的 encoding 字段取决于 entry-data 的内容。
-
如果
entry-data是字符串的时候,encoding第一个字节的前两位用于存储字符串长度的编码类型。然后是字符串的实际长度。 -
如果
entry是整数时,前2位都是1,。 接下来的两位用于指定在此标头之后将存储哪种类型.
由上面的两点,就足以确定 entry-data 的类型.
不同的类型和编码的概述如下:
# 字符串类型
-
a.| 00pppppp |: 含义是占用1个字节来表示长度小于或等于63个字节(6位)的字符串值。pppppp表示无符号的 6 位长度。 -
b.|01pppppp|qqqqqqqq|含义是用2个字节来表示小于等于16383(2^14)个字节的字符串的长度. (这里使用大端法计数) -
c.|10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt|含义是 使用 5 个字节来表示大于等于 16384 个字节长度的字符串,只有 4 个字节表示其最大长度为2^32-1. 低位的 6 位被设置成0.(这里使用大端法计数)
# 整数类型
d.|11000000|: 含义是用3个字节表示一个16位的有符号的短整形数 (short)。e.|11010000|: 含义是用5个字节 表示一个32位的有符合整数型 (int).f.|11100000|: 含义是用9个字节,表示一个64位的有符合长整数 (long)g.|11110000|: 含义是用4个字节表示24位有符号整数 (只占用 3 个字节)。PS: 有什么作用呢?前面说的小整形数。节约空间。即如图h.|11111110|: 含义是用2个字节表示一个8位的有符号小整形数。1个字节。i.|1111xxxx|:
除去上面列举的几类编码标识,还有|1111xxxx|的类别。
(xxxx在0000和1101之间) 立即4位整数。0到12之间的无符号整数。编码值实际上是1到13,因为不能使用0000和1111,因此应从编码的4位值中减去1以获得正确的值。j.|11111111|- 表示ziplist的特殊entry
这样,整个 Entry 的编码方式我们就搞明白了。
这些都是 Redis 中定义的规定, 所以我们记住就行了。如果让我们自己去设计一套编码方案的时候,我们就可以参考这种思路去设计。
# 那我们来举两个例子来试试身手吧。
# 例子 1: 25
# 编码方式
[0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
# 解析过程
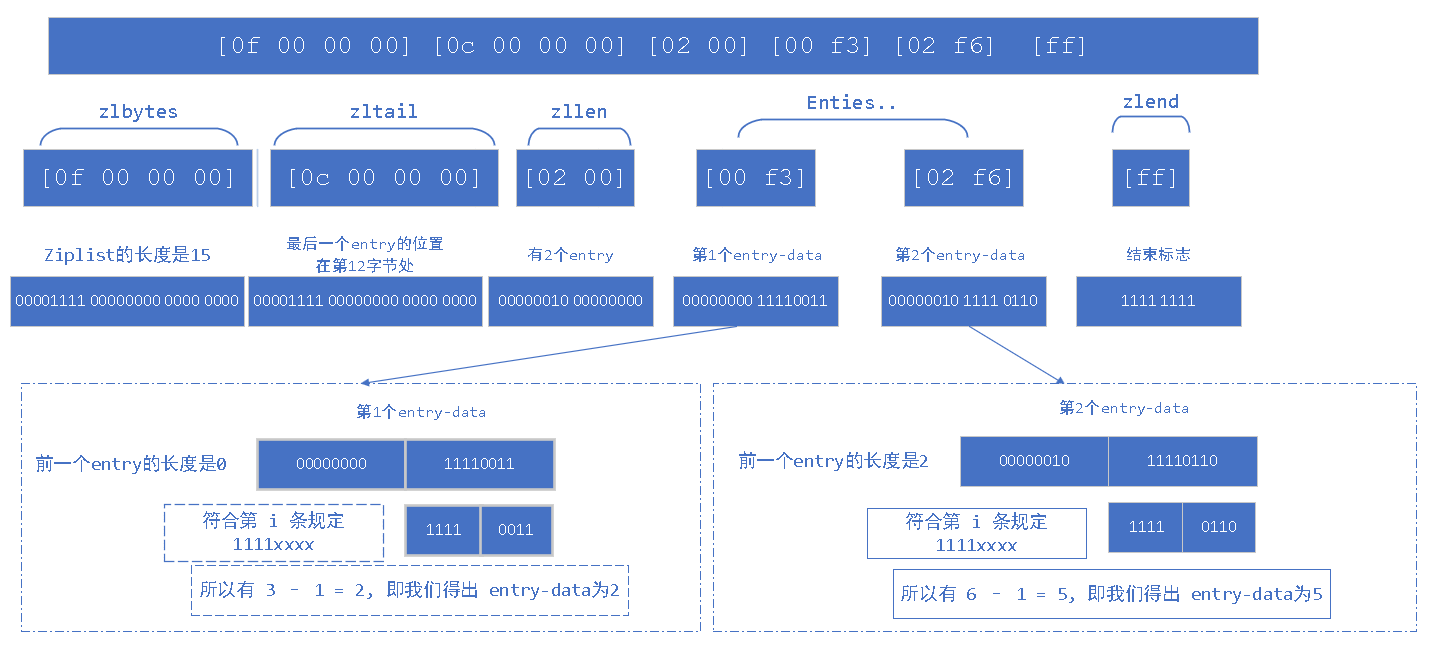

# 例子 2: Hello World
这里我们还是接着上面例子来讲,我们再设置一个 字符串 Hello World 。
# 编码格式
[02] [0b] [48 65 6c 6c 6f 20 57 6f 72 6c 64]
# 解析过程
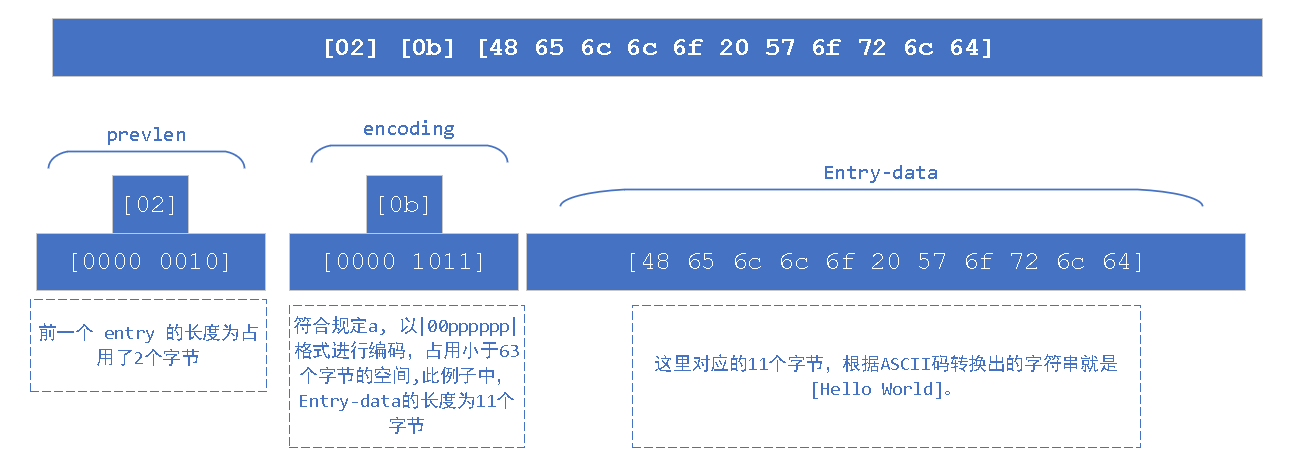
# 附录,ASCII 码表 (可展示字符)
以上内容,就是 Redis 的 ziplist 结构的内容了。
# 总结
本篇文章的内容主要是更加详细的分享了 ziplist 的这种数据结构的内部结构以及编码方式.
ziplist由5部分组成。存储了相关信息:<整个ziplist的长度><最后一个entry的偏移量><entry的总数><entries><表示结束的特殊entry>- 一个
entry由3部分组成,<前一个entry的长度><编码方式><entry的内容> - 其中 编码方式 是由 entry 的内容 决定的。有 10 条标准 (规定 / 协议)
- 引用了两个示例 (
25和Hello World),根据Redis的方式来解码.
# 最后
期待您的关注,希望和你一起遇见更好的自己

