# 书接上回
上一篇我们学习的 bitmap 这一 “数据类型” 。其内部是由 sds 这种种数据结构编码的。
如果不记得了,那就来坐穿梭机回去看看吧。 开始穿梭
接下来,我们继续学习一个新的 "数据类型" , 位图, HyperLogLogs .(注意啦,数据类型,我又加了引号!!)
# HyperLogLogs 简介
HyperLogLog 是一种概率数据结构,用于对唯一事物进行计数(从技术上讲,这是指估计集合的基数)。
注意哦, HyperlogLog 其实是一种基数计数算法,并非 Redis 独有的。
通常,对唯一项目进行计数需要使用与要计数的项目数量成比例的内存量,因为您需要记住过去已经看到的元素,以避免多次对其进行计数。但是,有一组算法会以内存换取精度:以 Redis 实施为例,您得出的带有标准误差的估计度量最终会小于 1% 。
该算法的神奇之处在于,您不再需要使用与所计数项目数量成比例的内存量,而可以使用恒定数量的内存!在最坏的情况下为 12k 字节,如果您的 HyperLogLogs 看到的元素很少,而且少得多。
Redis 中的 HyperLogLog 尽管在技术上是不同的数据结构,但被编码为 Redis字符串 ( sds ),因此您可以调用 GET 来序列化 HyperLogLogs ,然后调用 SET 来将其反序列化回服务器。这里我们在文末会大体翻一下源码。
接下来我们先看一下 HyperLogLog 有什么应用场景。
# HyperLogLog 的应用场景
根据 HyperLogLog 的特性来看,使用了一种概率性计数的功能,这样的功能有一个特点就是当数据特别大的时候,其统计的值是不准确的。什么意思呢?
就是比如统计一个网站的 PV , PV 数值是 123456789 或者 123456000 这两者的值对于管理者来讲是一样的。对于一些对精度要求不准确而且数据量很大的场景是非常适合的。
比如以下场景:计算网站的 PV,UV,统计日活,月活,统计用户每天搜索的词条数等等。
# HyperLogLog 的常用命令
HyperLogLog 应该是 Redis 所有结构中命令最少的了,只有三个命令。
PFADD key element [element ...]
添加元素。
如果一个 HyperLogLog 的估计的近似基数在执行命令过程中发了变化, PFADD 返回 1 ,否则返回 0 ,如果指定的 key 不存在,这个命令会自动创建一个空的 HyperLogLog 结构(指定长度和编码的字符串).
1 | 127.0.0.1:6379> pfadd k96 v1 v2 v3 |
PFCOUNT key [key ...]
当参数为一个 key 时,返回存储在 HyperLogLog 结构体的该变量的近似基数,如果该变量不存在,则返回 0 .
当参数为多个 key 时,返回这些 HyperLogLog 并集的近似基数,这个值是将所给定的所有 key 的 HyperLoglog 结构合并到一个临时的 HyperLogLog 结构中计算而得到的.
1 | 127.0.0.1:6379> pfadd k97 v1 v2 v3 v4 |
刚才说了, HyperLogLog 只是存储总数的一种结构,而且其值也会和实际值有偏差。我们一起来验证一下这个结果
我们往 Redis 中插入 10000 条数据,查看其 pfcount 的值是多少。
使用下面这个脚本去插入 ( java 实现)。公众号回复 RedisClient 可以获取完整源码。
1 | String host = "10.1.14.159"; |
插入完成之后,如下图,我们可以看到 pfCount 的结果是 9988 .
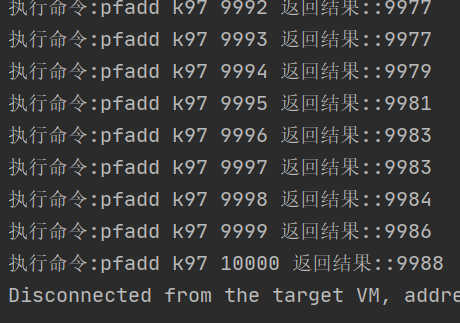
如果不相信我们可以 在 shell 里看看。
1 | 127.0.0.1:6379> pfcount k97 |
我这次测试正好相等,其实由于脚本的问题呢,从程序里获取的值和 shell 里获取的值,可能不一样,这种怎么解决呢? 使用脚本单独再执行一次,就会一样了。具体原因,不赘述了。
好了,我们插入了 10000 次,但是得出的值却是 9988 , 这也就验证了其不精确性。
PFMERGE destkey sourcekey [sourcekey ...]
将多个 HyperLogLog 合并( merge )为一个 HyperLogLog , 合并后的 HyperLogLog 的基数接近于所有输入 HyperLogLog 的可见集合( observed set )的并集.
合并得出的 HyperLogLog 会被储存在目标变量(第一个参数)里面, 如果该键并不存在, 那么命令在执行之前, 会先为该键创建一个空的 HyperLogLog .
1 | 127.0.0.1:6379> pfadd k98 v1 v2 v3 |
以上就是 HyperLogLog 的命令,老规矩我们下一步来看看 HyperLogLog 在 Redis 中是怎么实现的。
# HyperLogLog 的结构
在 Clion 中直接查找 hyperloglog ,就是 hyperloglog 的实现了。
我们可以看到有一个 struct
1 | struct hllhdr { |
这个就是 HyperLogLog 的存储结构了。这里大家大体有个印象就可以了。HyperLogLog 是一种基数估算算法的实现。后面我们会介绍这种基数估算法。
# 预告
最后一个 数据类型 geohash (多维空间点索引算法)!!!
# 最后
希望与你一起遇见更好的自己

